
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 자바
- Zeppelin
- Kafka
- Docker
- 간단
- 클러스터
- vue
- fastcampus
- gradle
- redash
- java
- aws
- SpringBoot
- 젠킨스
- ec2
- 레디스
- Mac
- 예제
- spring
- EMR
- Redis
- Jenkins
- 자동
- 설정
- login
- hive
- Cluster
- 로그인
- 머신러닝
- config
- Today
- Total
목록BIG DATA (56)
코알못
 [AWS] 로그수집 - logstash 큐 타입별 데이터 누락이 어느정도 발생할까?
[AWS] 로그수집 - logstash 큐 타입별 데이터 누락이 어느정도 발생할까?
logstash 의 내부 큐 타입이 memory 라면 데이터 누락이, persisted 방식이라면 데이터 누락이 없다고 공식 문서에 기재 되어있다. 그럼 정말 그럴까? 결론부터 말하자면 디스크 방식은 메모리 방식에 비해 누락이 적은것으로 누락이 없지는 않다. 물론 설정으로 누락 없도록 할 수 있으나 성능이 10배 정도 저하된다. 이전 게시글에서도 언급했듯이 성능과 데이터 누락 관계는 trade-off 관계로 둘중 하나 가중치를 두고 설정 해야 할 것이며 현재 넘어가는 데이터 또는 예상되는 데이터량, 아키텍쳐로 충분한 테스트를 거치고 최적의 설정값을 지정해야한다고 생각한다. 현재 메모리 방식으로 되어 있으나 장애의 상황도 많지 않아 우선 메모리 방식으로 가다가 추후 디스크 방식을 검토 하도록 하자. (아키..
 [로그수집] logstash 큐 타입에 따라 어떤 차이가 있을까?
[로그수집] logstash 큐 타입에 따라 어떤 차이가 있을까?
logstash 의 경우 내부 큐 타입은 2가지로 설정 가능하다. - memory (메모리) - persisted (디스크) 두가지 방식에 대한 차이를 구글링 해보았을때 아래와 같다. 구분 memory persisted 장애 발생시 큐에 저장된 데이터 유실 데이터 유실 없음 속도 빠름 느림 현재 회사에 설정된 queue type 은 memory 이며 데이터 유실이 발생할 수 있는 구조이다. 데이터 유실 없이 데이터 수집이 필요하여 persisted 사용시 성능 차이가 얼마나 발생하는지, 얼마나 디스크를 차지하는지를 이번시간에는 파악해보기로 한다. 우선 결과부터 말하자면 아래와 같다. 방식 데이터 건수 소요 시간 사용 메모리 사용 CPU 샤용 디스크 memory 3,000,000 5분 750MB 90% 0..
 elastic search 명령어
elastic search 명령어
# 로그 건수 확인 GET servicelog-2022.02.20/_count { "query": { "match_all": {} } } { "count" : 12, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 } } # 로그 데이터별 건수 확인 (group by message.keyword) GET servicelog-2022.02.20/_search { "size": 0, "aggs": { "item": { "terms": { "field": "message.keyword" } } } } { "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successfu..
 [로그 수집] logstash 장애시 이슈 없을까?
[로그 수집] logstash 장애시 이슈 없을까?
'filebeat > logstash > es' 로 현재 구성되어 있어 서비스 로그를 계속적으로 es 에 적재하고 있다. 그러나 logstash 설정 변경이 필요한 상황이라 logstash 를 재기동 해야 하는 상황으로 이때 이슈가 없을까? 에 대한 테스트를 진행해본다. 테스트는 아래와 같이 진행해본다. 1) 수동 restart 1. logstash 다운 $ kill -9 [logstash PID] 2. filebeat 에서 읽는 로그 파일에 데이터 추가 $ cat service.log {'name':'ParkHyunJun'} {'name':'LeeHoSeong'} {'name':'thewayhj'} {'name':'LeeNow'} {'name':'hongYooLee'} {'name':'test'} $ ..
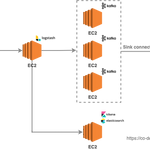 [로그 수집] 파이프 라인을 만들어 보자!
[로그 수집] 파이프 라인을 만들어 보자!
로그를 저장소인 S3에 저장하여 EMR 에서 활용할 것이다. 이를 위해서 로그를 아래 아키텍쳐와 같이 구성하는 실습을 진행해본다! 모두 버전은 7.6.0로 맞추었으며, mac 관련 설치 파일을 이용하였으니 맞는 os로 설치 해야 한다. =================== java =================== logstash 의 경우 실행시 java 설치 필요하다는 오류 발생 could not find java; set JAVA_HOME or ensure java is in PATH // 설치 가능한 버전 확인 $ yum list *java*jdk* Loaded plugins: extras_suggestions, langpacks, priorities, update-motd Available Pac..
 [AWS] EMR(hadoop) - Glue 메타 스토어 (HIVE, SPARK)
[AWS] EMR(hadoop) - Glue 메타 스토어 (HIVE, SPARK)
클러스터 생성시 Glue 메타 스토어를 Hive, spark 서비스의 경우 사용하도록 지정 할 수 있는데 선택 했을시와 선택 안했을시 차이를 보려고 한다. 클러스터를 아래와 같이 구성한다. 구분 지정 1번 클러스터 hive 만 glue 메타 스토어 지정 2번 클러스터 spark 만 glue 메타 스토어 지정 3번 클러스터 hive, spark glue 메타 스토어 지정 4번 클러스터 모두 glue 메타 스토어 지정하지 않음 결론 먼저 공개하면 아래와 같다. 구분\클러스터명 1번 클러스터 2번 클러스터 3번 클러스터 4번 클러스터 HIVE glue 데이터 로컬 mysql 데이터 glue 데이터 로컬 mysql 데이터 SPARK 오류 (하이브 메타 데이터를 바라보나 스파크는 glue 사용 설정을 하지 않아 ..
 [AWS] EMR(hadoop) - 오토 스케일링 해보자!
[AWS] EMR(hadoop) - 오토 스케일링 해보자!
AWS 하둡인 EMR 에는 오토 스케일링이라는 기능이 있다. 이는 하둡에는 없는 기능이며 AWS 에서 제공하는 기능으로 클라우드 서비스에 맞게 서버를 자동으로 스케일링 해주는 기능이다. 쉽게 말하자면 서버를 필요할때 서버를 늘려주고 필요없을때 반납해주는 기능이다. 예를 들어 하둡을 평상시에 사용안하다가 필요한 상황이 생기면 그때 기존 서버수 보다 더 투입하여 빠르게 처리하고 안쓸때 반납하는 기능이다. 오토 스케일링은 클러스터 구성시에도 가능하고 클러스터 구성후에도 설정 가능하며 실습을 진행해보자! 클러스터 생성시에 고급 설정을 들어간뒤, 2단계 하드웨어 설정에 있다. 현재 core 노드 3대, task 노드 3대로 총 6대의 노드 매니저가 작업을 진행할 것이다. 클러스터 스케일링중 EMR 관리자에 의한 ..
 [AWS] EMR(hadoop) - 자동 종료 해보자!
[AWS] EMR(hadoop) - 자동 종료 해보자!
AWS 하둡인 EMR의 경우 사용한 만큼 과금이 되는 구조로 클러스터 종료 시점까지 계속적으로 비용이 나간다. 사용한 만큼 비용을 지불하면 되니 필요할때만 기동하고 안쓸때는 클러스터를 종료를 하는것이 비용을 절감하는 방법이다. 클라우드 비용 과금 방지를 하기 위해 EMR 자동 종료 기능이 있으며 해당 기능을 사용하여 자동 종료를 하는 실습을 해본다. 자동 종료 기능은 클러스터 생성시 자동 종료 옵션을 지정 하거나 생성 한 뒤 지정할 수 있다. 우선 클러스터 생성 시점에 설정하는 방법은 아래와 같다. 설정하는 시간은 클러스터 인스턴스 모두 할당 받은 뒤 아무 작업 요청 없을때부터 경과 시간을 측정하며 만약 작업이 제출 되었다면 작업이 완전히 없을때 부터 경과 시간을 측정한다. 그 다음 클러스터를 생성한뒤에..