
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Cluster
- Zeppelin
- 클러스터
- 레디스
- Mac
- SpringBoot
- 예제
- spring
- EMR
- Redis
- Jenkins
- 간단
- config
- 젠킨스
- fastcampus
- 자바
- 설정
- vue
- hive
- Docker
- java
- login
- aws
- Kafka
- 로그인
- 머신러닝
- redash
- gradle
- ec2
- 자동
- Today
- Total
코알못
[AWS] 로그수집 - logstash 큐 타입별 데이터 누락이 어느정도 발생할까? 본문

logstash 의 내부 큐 타입이 memory 라면 데이터 누락이, persisted 방식이라면 데이터 누락이 없다고 공식 문서에 기재 되어있다.
그럼 정말 그럴까?
결론부터 말하자면
디스크 방식은 메모리 방식에 비해 누락이 적은것으로 누락이 없지는 않다. 물론 설정으로 누락 없도록 할 수 있으나 성능이 10배 정도 저하된다.
이전 게시글에서도 언급했듯이 성능과 데이터 누락 관계는 trade-off 관계로 둘중 하나 가중치를 두고 설정 해야 할 것이며 현재 넘어가는 데이터 또는 예상되는 데이터량, 아키텍쳐로 충분한 테스트를 거치고 최적의 설정값을 지정해야한다고 생각한다.
현재 메모리 방식으로 되어 있으나 장애의 상황도 많지 않아
우선 메모리 방식으로 가다가 추후 디스크 방식을 검토 하도록 하자. (아키텍쳐 재 설립중으로 우선 순위가 낮아 추후 개선사항으로 지정)
테스트는 아래와 같이 진행하였다.
유니크한 로그 데이터를 만드는 쉘 스크립트를 만들어 보자
vi start_create_log.sh
for i in {01..1000000}
do
echo "{'name':'data"$i"'}" >> service_auto.log
done
:wq!실행 하면 아래와 같이 100만개의 유니크한 로그가 만들어진다.
$ cat service_auto.log | wc -l
1000000
$ cat service_auto.log | tail -10
{'name':'data0999991'}
{'name':'data0999992'}
{'name':'data0999993'}
{'name':'data0999994'}
{'name':'data0999995'}
{'name':'data0999996'}
{'name':'data0999997'}
{'name':'data0999998'}
{'name':'data0999999'}
{'name':'data1000000'}유니크한 로그로 테스트를 진행해본다!
첫번째 데이터 누락 케이스가 발생하였다. (768개 누락)

두번쨰도 데이터 누락 케이스가 발생하였다. (256개 누락)
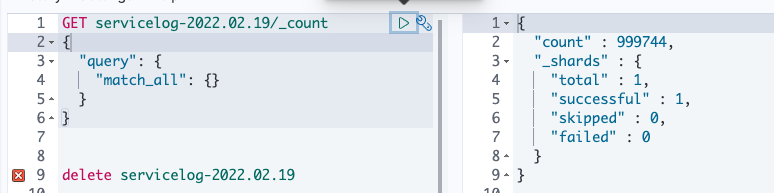
세번째도 데이터 누락 케이스가 발생 하였다.
// 전체 카운트
GET servicelog-2022.02.19/_count
{
"query": {
"match_all": {}
}
}// 결과
{
"count" : 999192,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}
만약 장애 없을시 정상적으로 들어온다.
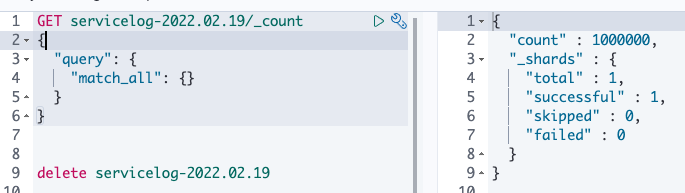
이제 디스크 방식으로 누락 테스트를 진행한다.
메모리 방식에서는 es 에 옮겨진 로그 건수가 대상 로그 건수 보다 적어 유니크 카운트를 측정할 필요가 없었지만
디스크 방식에서는 영구 큐에 있는 데이터를 다시 보낼것이기에 es 에 옮겨진 건수가 100만건 또는 그 이상일 것으로 보여 유니크 건수를 측정해야한다.
그러나 유니크 건수 측정시 디스크 방식임에도 불구하고 데이터 누락이 발생하였다.

맞게 조회한건지 궁금하여 계속적으로 es 쿼리에 대해서 찾아봤으며
결론적으로 es 에서는 정확한 유니크 수치를 확인하기 어렵다고 하였다. (대략적인 수치만 확인 가능하다고 한다.)
그래서 다른 방식으로 저장하기로 하였다. (kafka를 이용해 로컬에 적재해본다.)
# logstash > kafka
input {
beats {
port => 5044
host => "0.0.0.0"
}
}
#filter {
# mutate {
# gsub => ["message","'","\""]
# }
#}
output {
stdout{
codec => dots
}
#elasticsearch{
#hosts => "genie-hong-06"
#index => "servicelog-%{+yyyy.MM.dd}"
#}
kafka {
bootstrap_servers => "kafka-01:9092,kafka-02:9092,kafka-03:9092"
#codec => json
codec => line { format => "%{message}"}
topic_id => "logstash-test"
}
}# connect > s3
{
"name": "logstash-test",
"config": {
"connector.class": "io.confluent.connect.s3.S3SinkConnector", // s3 connect로 s3에 연결
"format.class": "io.confluent.connect.s3.format.json.JsonFormat", // json 형식으로 받는다
"storage.class": "io.confluent.connect.s3.storage.S3Storage", // s3 저장소 사용
"topics.regex" : "logstash-test", // 읽을 토픽
"flush.size": 1000000, // 100만개씩 s3에 저장
"rotate.interval.ms" : 600000, // 10분 간격으로 s3에 flush (데이터 누락 또는 중복 발송으로 인해 s3 에 적재되지 않을 가능성이 있어 10분(100만건 최대 전송 시간) 간격으로 저장 되도록함)
"s3.bucket.name": "emr-hong", // s3 버킷명
"s3.region": "ap-northeast-2", // s3 리전
"topics.dir": "data/topics", // s3 저장할 위치
"locale": "ko_KR", // 읽어 들일 데이터 언어
"timezone": "Asia/Seoul" // timezone
}
}데이터 유니크 건수 확인 명령어
$ cat logstash-test+0+0000000040.json | sort | uniq | wc -l준비는 완료 되었으니 테스트 진행해본다.
// S3

// 전체 건수
cat logstash-test+0+000* | wc -l
1001684// 유니크 건수
$ cat logstash-test+0+000* | sort | uniq | wc -l
998316데이터 누락이 발생하여 어디서 누락되는지 검색 해보았으며
공식 문서에 check point 작업 도중 logstash 장애시 체크 포인트 못한 부분에 대해 누락이 발생할 수 있다고 하여 check point 주기를 늘리면 누락을 방지 할 수 있다고 되어있다. 그러나 디스크 I/O 를 계속적으로 하여 성능적으로 이슈가 있을 수있다.
- https://www.elastic.co/guide/en/logstash/current/persistent-queues.html
Persistent queues (PQ) | Logstash Reference [8.0] | Elastic
If Logstash is terminated, or if there is a hardware-level failure, any data that is buffered in the persistent queue, but not yet checkpointed, is lost.
www.elastic.co
관련 설정을 변경하고 테스트를 해본다.
(default : 1024) > 1
$ vi config/logstash.yml
queue.checkpoint.writes=1테스트 해보니 약 40분 소요되어 기존 영구 저장 방식 테스트한 3분 보다 약 14배 더 소요되는 것이다.
데이터 유실이 없는것을 볼 수 있다.
// 전체 카운트
$ cat logstash-test+0+0002* | wc -l
1000446
// 유니크 카운트
$ cat logstash-test+0+0002* | sort | uniq | wc -l
1000000서비스 운영하기 위해서 1개의 이벤트마다 처리하는것은 부하가 심하므로 유실 되지 않는 선으로 설정을 조정 하도록 한다. (14배는 솔직히 심해..ㅆ..)
$ vi config/logstash.yml
queue.checkpoint.writes=500500으로 설정해도 약 3분 안에 처리 된다.
$ cat logstash-test+0+000* | wc -l
1001201
$ cat logstash-test+0+000* | sort | uniq | wc -l
1000000900으로 변경해본다.
$ vi config/logstash.yml
queue.checkpoint.writes=900$ cat logstash-test+0+000* | sort | uniq | wc -l
1000000
$ cat logstash-test+0+000* | wc -l
1002087$ cat logstash-test+0+000* | sort | uniq | wc -l
1000000
$ cat logstash-test+0+000* | wc -l
1002045$ vi config/logstash.yml
queue.checkpoint.writes=1000$ cat logstash-test+0+000* | wc -l
1001365
$ cat logstash-test+0+000* | sort | uniq | wc -l
1000000$ vi config/logstash.yml
queue.checkpoint.writes=1010$ cat logstash-test+0+001* | wc -l
1001626
$ cat logstash-test+0+001* | sort | uniq | wc -l
1000000$ vi config/logstash.yml
queue.checkpoint.writes=1020$ cat logstash-test+0+001* | wc -l
1001945
$ cat logstash-test+0+001* | sort | uniq | wc -l
1000000$ vi config/logstash.yml
queue.checkpoint.writes=1021 $ cat logstash-test+0+001* | sort | uniq | wc -l
1000000
$ cat logstash-test+0+001* | wc -l
1001063$ vi config/logstash.yml
queue.checkpoint.writes=1022$ cat logstash-test+0+001* | sort | uniq | wc -l
1000000
$ cat logstash-test+0+001* | wc -l
1001756$ vi config/logstash.yml
queue.checkpoint.writes=1023$ cat logstash-test+0+001* | wc -l
1001522
$ cat logstash-test+0+001* | sort | uniq | wc -l
1000000$ vi config/logstash.yml
queue.checkpoint.writes=1024$ cat logstash-test+0+000* | wc -l
1000000
$ cat logstash-test+0+000* | sort | uniq | wc -l
997955
100만개 데이터 전송시 현재 설정으로는 체크 포인트 1023까지는 데이터 누락없이 전송 된다.
메모리 방식이랑은 관련없는 설정이라는데 실제로 그런지 테스트를 해보았으나 해당 옵션은 공식문서대로 적용이 안되는것으로 보인다.
$ vi config/logstash.yml
queue.checkpoint.writes=1
$ cat logstash-test+0+001* | sort | uniq | wc -l
999862
$ cat logstash-test+0+001* | wc -l
999936
그 다음 테스트는 정상 프로세스 종료시 메모리 방식에 이슈 없는지 확인해본다.
$ kill -15 [logstash pid]
누락이 없음을 확인하였다. 재기동을 해야하는 상황에서는 위와 같이 종료하도록 하자.
$ cat logstash-test+0+002* | wc -l
1004096
$ cat logstash-test+0+002* | sort | uniq | wc -l
1000000결론,
디스크 방식은 메모리 방식에 비해 누락이 적은것으로 누락이 없지는 않다. 물론 설정으로 누락 없도록 할 수 있으나 성능이 10배 정도 저하된다.
이전 게시글에서도 언급했듯이 성능과 데이터 누락 관계는 trade-off 관계로 둘중 하나 가중치를 두고 설정 해야 할 것이며 현재 넘어가는 데이터 또는 예상되는 데이터량, 아키텍쳐로 충분한 테스트를 거치고 최적의 설정값을 지정해야한다고 생각한다.
<참고>
- 영구 저장 방식 큐 내용으로 데이터 자체가 저장되어 있는것이 아닌 데이터+클래스정보? 이런게 들어있어서 큐 사이즈가 데이터 유실 될수 있는 사이즈라고 단정 지을 수 없다.
$ cat checkpoint.10
�a�ac
$ cat page.10
.RubyStringnap-northeast-2�zzz�xorg.logstash.ConvertedMap�bid�torg.jruby.asde���eimage�xorg.logstash.ConvertedMap�bid�torg.jruby.RubyStringuami-acvbd�����gmessage�torg.jruby.RubyStringv{'name':'data0000112'}�einput�xorg.logstash.ConvertedMap�dtype�torg.jruby.RubyStringclog���eagent
...- elastic 명령어
elastic search 명령어
# 로그 건수 확인 GET servicelog-2022.02.20/_count { "query": { "match_all": {} } } { "count" : 12, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 } } # 로그 데이터별 건수..
co-de.tistory.com
- 정상 프로세스 종료(SIGTERM) / 강제 종료 (SIGKILL)
logstash 의 경우 정상 프로세스 종료일시 진행중인 작업에 대해서는 모두 처리하고 종료 하므로 데이터가 손실되지 않으며 데이터 복제도 발생하지 않는다.
그러나 강제 종료시 진행중인 작업이 강제로 종료 되기에 재처리하여 중복 데이터가 발생할 수 있다.
$ kill -9 // 강제 종료
$ kill -15 // 정상 프로세스 종료 or ctrl + chttps://www.elastic.co/kr/blog/logstash-persistent-queue
Logstash Persistent Queue
Logstash introduced Persistent Queues to avoid data loss in case of abnormal failures and can grow in size on disk to help handle data ingestion spikes.
www.elastic.co
- logstash queue check pointing
체크 포인트는 2가지로 나눠진다.
1. head check point
- input 에 대한 check point 로 input 서비스에 ack를 보내고 실제
2. tail check point
'BIG DATA' 카테고리의 다른 글
| [Redash] 데이터 시각화 도구를 설치 해보자! (0) | 2022.02.25 |
|---|---|
| [로그수집] 서비스 별로 다른 저장소에 로그를 적재하고 싶다면 ? (0) | 2022.02.21 |
| [로그수집] logstash 큐 타입에 따라 어떤 차이가 있을까? (0) | 2022.02.20 |
| elastic search 명령어 (0) | 2022.02.20 |
| [로그 수집] logstash 장애시 이슈 없을까? (0) | 2022.02.14 |



