
코알못
Word2vec 본문
# 자연어 처리 기술
[1] 카운트 기반 방법 (count-based methods)
- 특정 단어가 이웃 단어들과 같이 등장한 횟수를 통해 예측
[2] 예측 모델 (predictive model)
- 단어의 의미의 유사도를 학습하여 예측
- ex ) Word2vec
# Word2vec
- 구글 라이브러리
- 자연어 처리 기술
- 워드 임베딩(Word embedding) 방식 (아래 참고 개념)
- 단어(Word)를 벡터(Vector)로 바꿔주는 방법
* 백터란 공간에서 크기와 방향을 가지는 것

- 모델
1) CBOW(Continuous Bag of Words)
- 주변 단어로 중심 단어를 예측하는 것

- 순서
1. 윈도우(한번에 학습할 단어 수) 크기 지정
- N(윈도우크기)=1 라면, 주변 단어 수는 2N = 2 * 1
2. 슬라이딩 윈도우(sliding window)
- 윈도우를 계속 움직여서 주변 단어와 중심 단어 선택을 바꿔가며 학습을 위한 데이터 셋을 만들기.
3. 학습 하면서 (W, b를 업데이트) 손실값이 적은 W, b 를 찾는다.
- 아키텍쳐
* 아래 예제에서는 학습할 W, b의 총 수는 '(입력으로 들어가는 노드수 x 출력으로 나가는 노드수) + 출력으로 나가는 노드수' :: ((4xn)+n+(n*4)+4)
* softmax 쓰는 이유 : 계산 시간을 단축하기 위해
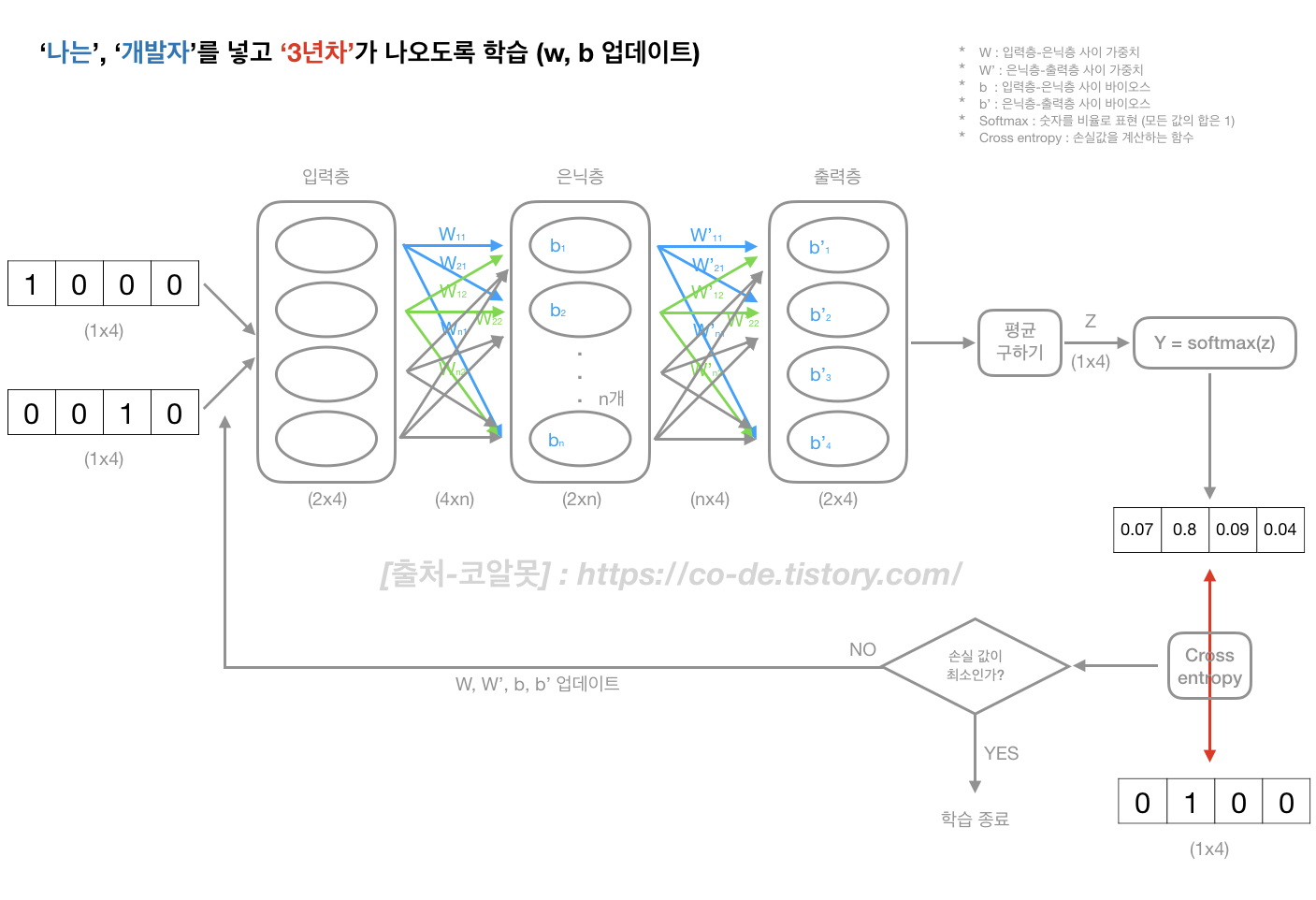
2) Skip-Gram
- 중심 단어로 주변 단어를 예측하는 것
- w,b 업데이트 횟수(학습수)가 CBOW 보다 많아 성능이 좋음(윈도우 크기가 2라면, CBOW :: 1번 / skip-gram :: 4번) <output 기준으로 학습>
* CBOW : (입력) 나는, 개발자 / (출력) 3년차
* skip-gram : (입력) 3년차 / (출력) 나는 :: (입력) 3년차 / (출력) 개발자

- 예제
1) 장바구니에 담은 상품 데이터를 활용한 유사 상품 추천
:: github.com/works-code/word2vec
# 알고 가면 좋은 내용
1) 인코딩 (encoding)
- 학습 데이터를 문자로 입력하는 것이 안되어 숫자로 변형하는 작업

2) one-hot encoding
- N개의 단어를 각각 N차원의 벡터로 표현하는 방식
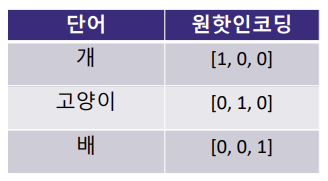
- 단어의 의미 또는 개념 차이를 벡터안에 담지 못한다는 큰 단점
- 벡터간 거리가 같아 각 단어가 유사한지 파악하기 어려움

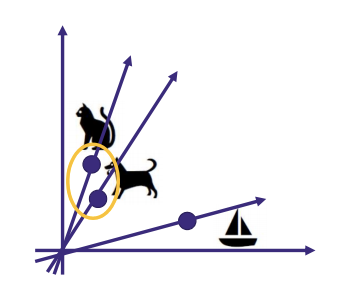
3) 워드 임베딩(Word embedding)
- 단어의 의미를 최대한 담은 벡터
- ex) [0.2,0,4,0.5 ... 0.8,8]
4) 가중치 행렬
- 학습 시킨 w, w' 를 의미하며 해당 값을 임베딩 벡터로 사용 한다.
- 둘중 하나를 사용하거나 w, w' 의 평균을 구해서 사용함
5) 학습에 사용하는 softmax값, 학습후 두 단어 간의 코사인 유사도
- 학습에서 사용하는 softmax 값은 단어를 벡터화(w, w') 시키기 위해 학습한 값(0~1사이값)
- 학습 결과인 벡터값을 이용해서 단어 간 코사인 유사도를 구해 유사한 정도를 계산(-1~1 사이값)
# Reference
- songys.github.io/2019LangCon/data/whatisnlp.pdf
'PYTHON' 카테고리의 다른 글
| [selenium] 손쉽게 브라우저 자동 캡쳐 기능 만들기 (0) | 2021.05.02 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 - 3장 (0) | 2020.11.08 |
| 파이썬 머신러닝 완벽 가이드 - 2장 (0) | 2020.10.31 |
| 파이썬 머신러닝 완벽 가이드 - 1장 (0) | 2020.10.31 |
| Word2vec - 코사인유사도 (0) | 2020.10.23 |



