
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 젠킨스
- Zeppelin
- 레디스
- 클러스터
- 로그인
- 간단
- SpringBoot
- config
- redash
- Kafka
- 예제
- Docker
- EMR
- vue
- java
- 자동
- spring
- Mac
- ec2
- fastcampus
- 머신러닝
- login
- Cluster
- aws
- gradle
- Redis
- 자바
- Jenkins
- hive
- 설정
- Today
- Total
코알못
레인저 적용 EMR의 zepplelin에서 spark 사용 본문
예시는 ldap에 corin, test 라는 유저가 있고 해당 계정으로 zeppelin 로그인하여 스파크를 사용하며 스파크로 접근 가능한 테이블을 ranger로 권한 제어 하는 예시이다.
아래 두 스크립트 생성 (master, core, task, spot 모든 노드에 적용되는 스크립트로 EMR 부트스트랩에 등록 예정)
ranger_host_setting.sh
sudo chmod 777 /etc/hosts
echo '172.X.X.X ranger.X.co.kr' >> /etc/hostslinux_adduser.sh
USER_LIST='corin test'
for USER in $USER_LIST; do
sudo adduser $USER
done아래 두 스크립트 생성 (마스터 노드에서만 실행되는 스크립트로 EMR 단계에 등록 예정)
hdfs_adduser_with_kerberos.sh
USER_LIST='geniepro'
for USER in $USER_LIST; do
sudo kadmin.local -q "addprinc -randkey $USER"
sudo kadmin.local -q "ktadd -k /tmp/$USER.keytab $USER"
sudo chown rangeradmin:root /tmp/$USER.keytab
sudo chmod 755 /tmp/$USER.keytab
hdfs dfs -mkdir /user/$USER
hdfs dfs -chown $USER:$USER /user/$USER
donezeppelin_setting_with_kerberos.sh
sudo mv /usr/lib/zeppelin/bin/interpreter.sh /usr/lib/zeppelin/bin/interpreter.sh_BKP
sudo aws s3 cp s3://[첨부한 파일을 올린 S3 버킷 및 디렉토리]/interpreter.sh /usr/lib/zeppelin/bin/
sudo chown root:root /usr/lib/zeppelin/bin/interpreter.sh
sudo chmod 755 /usr/lib/zeppelin/bin/interpreter.sh
sudo mv /etc/zeppelin/conf/zeppelin-env.sh /etc/zeppelin/conf/zeppelin-env.sh_BKP
sudo aws s3 cp s3://[첨부한 파일을 올린 S3 버킷 및 디렉토리]/zeppelin-env.sh /etc/zeppelin/conf/
sudo chown root:root /etc/zeppelin/conf/zeppelin-env.sh
sudo chmod 644 /etc/zeppelin/conf/zeppelin-env.sh
sudo mv /etc/zeppelin/conf/interpreter.json /etc/zeppelin/conf/interpreter.json_BKP
sudo aws s3 cp s3://[첨부한 파일을 올린 S3 버킷 및 디렉토리]/interpreter.json /etc/zeppelin/conf/
sudo chown zeppelin:zeppelin /etc/zeppelin/conf/interpreter.json
sudo chmod 600 /etc/zeppelin/conf/interpreter.json
sudo mv /etc/zeppelin/conf/shiro.ini /etc/zeppelin/conf/shiro.ini_BKP
sudo aws s3 cp s3://[첨부한 파일을 올린 S3 버킷 및 디렉토리]/shiro.ini /etc/zeppelin/conf/
sudo chown zeppelin:zeppelin /etc/zeppelin/conf/shiro.ini
sudo chmod 655 /etc/zeppelin/conf/shiro.ini
sudo cp /etc/sudoers /home/hadoop/sudoers
sudo chown hadoop:hadoop /home/hadoop/sudoers
sudo chmod 700 /home/hadoop/sudoers
echo "zeppelin ALL=(ALL) NOPASSWD:ALL" >> /home/hadoop/sudoers
sudo chown root:root /home/hadoop/sudoers
sudo chmod 440 /home/hadoop/sudoers
sudo mv /home/hadoop/sudoers /etc/
sudo systemctl restart zeppelinEMR 보안 구성 생성
prod-emr-security

PEM 파일은 AWS Secrets manager에 등록 하며 (레인저 관련 인증서는 해당글 참고)
관리 PEM 암호만 인증서(combined.pem로 해당글의 chain 파일)이며 나머지 서비스에 적용될 PEM 보안 암호는 키체인(key.pem, combined.pem 정보 모두 있는 인증서로 해당글의 key_chain 파일)을 선택하면 된다.


위에서 사용한 파일은 해당 파일로 'X 또는 []' 로 되어 있는 부분은 설정 수정하여 S3 에 업로드 하여 사용
Ranger 기반 EMR 기동하는 람다 스크립트 생성하고 테스트 버튼을 눌러 EMR 을 실행한다.
import json
import boto3
client=boto3.client('emr')
s3=boto3.resource('s3')
emr_config_json=''
def lambda_handler(event, context):
emr_create()
return { 'statusCode': 200, 'body': 'emr create success!!!' }
def emr_create():
get_emr_config()
response = client.run_job_flow(
Name= "PROD-EMR",
LogUri= "s3://[버킷]/logs/",
ReleaseLabel= "emr-6.5.0",
Instances={
"Ec2KeyName":"data",
"Ec2SubnetId":"subnet-XX",
"EmrManagedMasterSecurityGroup":"sg-XX",
"EmrManagedSlaveSecurityGroup":"sg-XX",
"ServiceAccessSecurityGroup":"sg-XX",
"AdditionalMasterSecurityGroups": ["sg-X","sg-X"],
"KeepJobFlowAliveWhenNoSteps": True,
"InstanceGroups": [{"InstanceCount":4,"CustomAmiId":"ami-X","EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"SizeInGB":128,"VolumeType":"gp3","Throughput":600,"Iops":6000},"VolumesPerInstance":1}]},"InstanceRole":"CORE","InstanceType":"m6g.4xlarge","Name":"Core - 2"},{"InstanceCount":1,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"SizeInGB":32,"VolumeType":"gp3"},"VolumesPerInstance":1}]},"InstanceRole":"MASTER","InstanceType":"m6g.xlarge","Name":"Master - 1"}]
},
Applications = [{"Name": "Hadoop"},{"Name": "Hive"},{"Name": "ZooKeeper"},{"Name": "Zeppelin"},{"Name": "Tez"},{"Name": "Hue"},{"Name": "Ganglia"}],
Configurations = emr_config_json,
JobFlowRole = "EMR_EC2_DefaultRole",
ServiceRole = "EMR_DefaultRole",
ManagedScalingPolicy={
"ComputeLimits": {
"MaximumCapacityUnits": 20,
"MaximumCoreCapacityUnits": 4,
"MaximumOnDemandCapacityUnits": 4,
"MinimumCapacityUnits": 4,
"UnitType": "Instances"
}
},
AutoScalingRole="EMR_AutoScaling_DefaultRole",
Tags=[
{
"Key": "Name",
"Value": "PROD-EMR"
},
{
"Key": "createby",
"Value": "corin"
},
{
"Key": "env",
"Value": "prod"
}
],
BootstrapActions=[
{ # 고정 IP 기능 이용할시 사용
"Name": "assign_private_ip.py",
"ScriptBootstrapAction": {
"Args": ["172.X.X.X","ap-northeast-2"], # 고정할 IP
"Path": "s3://[버킷 및 디렉토리]/assign_private_ip.py"
}
},
{
"Name": "ranger_host_setting.sh",
"ScriptBootstrapAction": {
"Path": "s3://[버킷 및 디렉토리]/ranger_host_setting.sh"
}
},
{
"Name": "linux_adduser.sh",
"ScriptBootstrapAction": {
"Path": "s3://[버킷 및 디렉토리]/linux_adduser.sh"
}
}
],
SecurityConfiguration="prod-emr-security",
KerberosAttributes={
"KdcAdminPassword": "[설정할 패스워드]",
"Realm": "COMPUTE.INTERNAL"
},
Steps=[
{
"Name": "hdfs_adduser_with_kerberos.sh",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "s3://ap-northeast-2.elasticmapreduce/libs/script-runner/script-runner.jar",
"Args": [
"s3://[버킷 및 디렉토리]/hdfs_adduser_with_kerberos.sh"
]
}
},
{
"Name": "zeppelin_setting_with_kerberos.sh",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "s3://ap-northeast-2.elasticmapreduce/libs/script-runner/script-runner.jar",
"Args": [
"s3://[버킷 및 디렉토리]/zeppelin_setting_with_kerberos.sh"
]
}
}
],
EbsRootVolumeSize=20
)
# EMR 커스텀 설정 파일
def get_emr_config():
content_object = s3.Object('[버킷명]', '[디렉토리 맨 앞 '/' 생략하고 입력]/emr_config_analysis.json')
file_content = content_object.get()['Body'].read().decode('utf-8')
global emr_config_json
emr_config_json = json.loads(file_content)관련 파일을 해당 첨부 파일 '[], X' 부분 수정하여 사용
레인저 설정

두개 설정 필요

아래와 같이 설정하며 tb_test 테이블을 제외하고 모든 테이블을 corin, test 유저가 접근 가능하도록 한다.

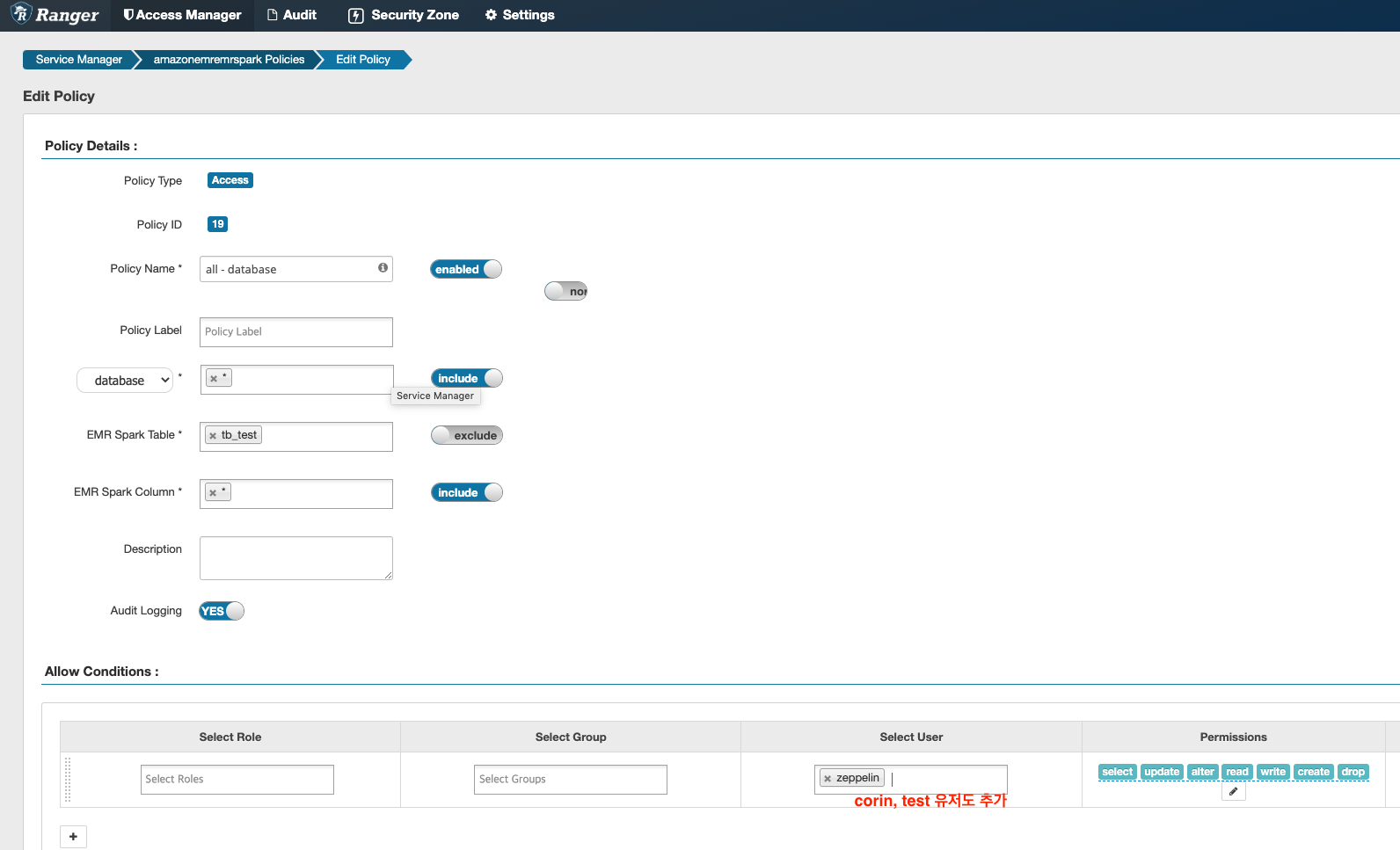
적용이 되었는지 아래 업데이트 일자 Active 까지 됐는지 확인 하고 적용 안되었으면 빨간색으로 표기되나 현재 정상적으로 적용되어 검은색이다.

이제 제플린에서 테스트 해보면 접근 가능한 테이블은 정상 조회 되며, tb_test 테이블은 오류 발생한다.

보안 구성에 설정한 클라우드 워치 로그 그룹에 가서 확인하면 정상적으로 오딧 로그(활동 로그)를 볼 수 있다.


끝!
'ETC' 카테고리의 다른 글
| [kubernetes] ReplicaSet 실습 - pod 종료, template 수정 (1) | 2023.05.20 |
|---|---|
| [kubernetes] ReplicaSet 란? (0) | 2023.05.20 |
| Ranger 설정 수정 및 인증서 교체 (0) | 2023.05.17 |
| Ranger 적용된 EMR 집계 로그 S3 저장 안되는 이유 (0) | 2023.05.16 |
| [kubernetes] 쿠버네티스 Label, Selector 실습 (0) | 2023.05.07 |


