
코알못
[Redash] 데이터 시각화 도구를 이용 해보자! - 다른 저장소 결과간 데이터 조인 본문

DB 종류가 다르다면 두 데이터간의 조인이 불가능하다.
물론 redash 에서도 불가능하다.
그러나 각각의 DB에서 조회한 결과 끼리 join 하여 새 데이터를 만들어 낼 수 있다!
그럼 실습을 진행해보자!
아래 '장르별 카운트', '탑 장르명' 두 데이터의 결과를 조합하여 'TOP 장르의 카운트'를 출력해본다.
// 장르별 카운트
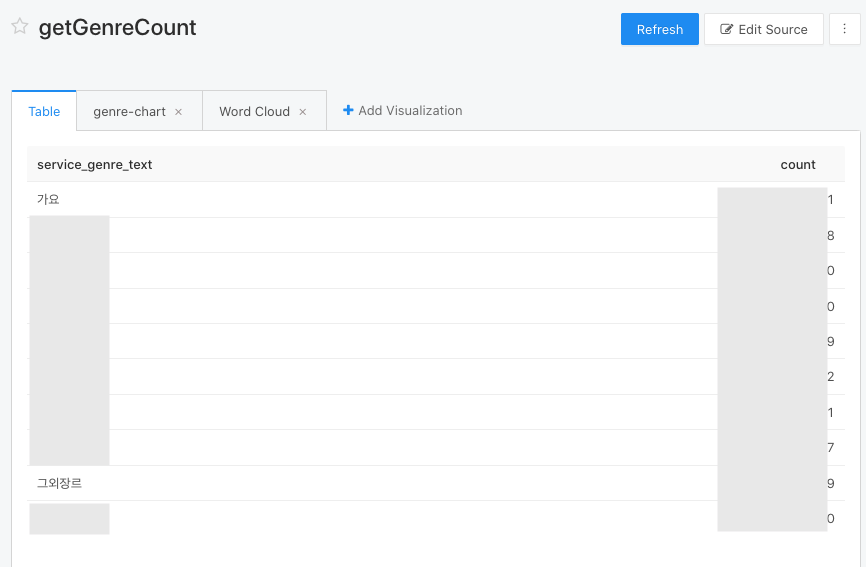
// 탑 장르
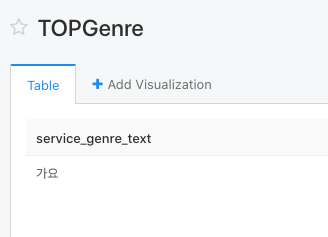
우선 아래와 같이 Query Results 를 만들어 본다.

최종적으로 탑 장르의 카운트를 출력할것이니 'TopGenreCount' 라고 적는다.

저장을 완료 했다면 '장르별 카운트', '탑 장르명' 각각의 쿼리 번호를 알아야 한다.

각각 쿼리를 클릭해보면 주소창 상단에 쿼리 번호가 나오며 1번 이며

탑 장르의 경우 쿼리번호가 3이다.

쿼리 조회시 query_[query id] 으로 해당 테이블 결과 조회 가능하며
실제 실행해봤을시 쿼리가 제출되어 view 테이블 개념으로 보면 될 것 같다.
이제 새로운 쿼리를 만들어 조인해보자!
아래와 같이 쿼리를 생성한다.

좀전에 만든 result querys 를 선택하고 쿼리를 생성하여 실행 한다.

정상적으로 다른 두 DB 의 결과 데이터를 가져왔다.
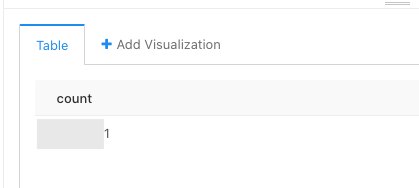
만약 데이터를 추가 조회하지 않고 현재 나온 결과만 가지고 조회하려고 하면 캐싱된 데이터로 더 빠르게 조회할 수 있다.
cached_query_[query id] 를 이용하면 되며 1초 만에 결과가 나온다.

CSV 파일 다운로드 링크가 있다면 CSV 파일을 불러 올수 있다.
가져와서 조인 해보자
아래와 같이 데이터 소스를 CSV type 으로 만든다.

원하는 데이터 소스 명칭을 적는다.

query 를 새로 생성하여 좀전에 만든 CSV 데이터 소스를 클릭한뒤 url : "csv 파일 다운로드 주소" 를 적고 Execute 하면
아래와 같이 데이터를 정상적으로 불러온다.

다음으로 CSV 파일(장르 설명:6)과 이전에 만들어둔 쿼리(장르별 카운트:1)와 조인 한다.
아래와 같이 정상적으로 데이터 조회 되는것을 볼 수 있다.

끝!
'BIG DATA' 카테고리의 다른 글
| [ Zeppelin] 스케쥴링 기능을 이용해보자! (0) | 2022.03.07 |
|---|---|
| [Zeppelin] 설치 하고 이용해보자! (0) | 2022.03.07 |
| [Redash] 사용자 초대 (0) | 2022.02.27 |
| [Redash] 데이터 시각화 도구를 이용 해보자! - Slack (결과전송) (0) | 2022.02.27 |
| Redash VS Tableau (0) | 2022.02.26 |



