
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 예제
- Cluster
- Zeppelin
- EMR
- fastcampus
- config
- Kafka
- hive
- spring
- 로그인
- redash
- 클러스터
- 레디스
- 설정
- 젠킨스
- java
- 자동
- vue
- aws
- Mac
- Docker
- ec2
- Jenkins
- 머신러닝
- Redis
- SpringBoot
- 자바
- 간단
- login
- gradle
- Today
- Total
코알못
[AWS] EMR(hadoop) - 만들어 보자! 본문

우선 EMR 에 대해서 알아보면 아래와 같다.
- AWS 에서 제공하는 하둡 서비스
- 운영 부담을 줄여 준다.
- 서버를 원하는대로 변경 할 수 있어 클러스터에 대한 유연성과 확장성이 좋다.
- 빠르게 하둡을 설치하여 이용할 수 있다.
기존 하둡과 비교하면 아마존 하둡인 EMRFS는 저장소를 S3에 저장할 수 있다는 점이 다르며 아마존의 서비스를 적극적으로 활용할 수 있다.
S3 의 경우에도 하둡과 동일한 분산 저장소이기에 무한대로 저장도 가능하니 디스크 증설이 필요 없으며, 디스크 파일은 URL 로 공유도 가능하니 파일 접근 및 공유가 쉽다.
그러나 하둡의 경우 replica 를 통해 데이터 유실을 방지하고 데이터 처리 성능을 빠르게 하나 S3 의 경우에는 일반 파일 시스템처럼 백업 하면 복제 기능은 동일하게 할 수 있으나 데이터 유실 방지 용이지 데이터 처리 성능을 빠르게 하지는 않는다.(읽기 요청한 파일에만 읽지 복제본을 읽지는 않기 때문)
그러나 S3가 하둡에서 이용한 디스크 보다 성능이 좋다면 어떨까? 데이터 처리 성능, 데이터 유실 가능성이 S3가 더 높다면 필요 없을 것이다. 그래서 없는것이 아닐까?? 라는 생각을 가져보고 실제 이용해보면서 그 부분은 확인한다.

우선 AWS 콘솔에 접속 하여 emr 을 검색 한다.
클러스터 생성을 클릭한다.
저자의 경우 고급설정을 통해 상세하게 설정 한다.

총 4단계로 이뤄져있으며 단계 별로 차근차근 설정해 본다.

각 단계별 설정에 대한 설명은 아래와 같이 쉽게 풀어 정리 하였으니 참고하여 설정 한다.
| 단계 | 설정 | 구분 | 내용 | 설정 |
| 1단계 : 소프트웨어 | 소프트웨어 구성 | 이미지 | 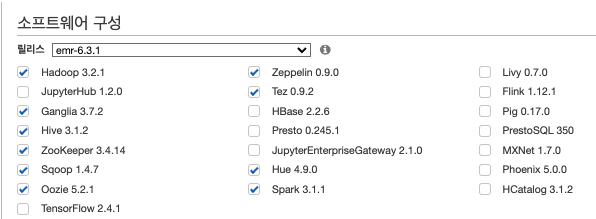 |
|
| 릴리즈 | 원하는 버전을 설치한다. | |||
| 서비스 | 현재 사용하고 있는 서비스 및 사용하고 싶은 서비스를 설정한다. 이는 나중에 운영하면서 추가도 가능하다. | |||
| 여러 마스터 노드 | 이미지 |  |
하둡 자체적으로 운영하면서 마스터 노드 한대 운영시 장애 발생한 적이 없어 필요 하지 않아 보이나 추가 할 수 있다면(돈이 된다면) 하는것이 좋다.(테스트 EMR 에는 마스터 노드 1대로 한다.) | |
| 설명 | 여러 마스터 노드를 두면 마스터 노드 장애시 에도 정상 서비스 가능하다. (=고가용성) 단, 마스터 노드는 최초 구성후 변경이 불가능 하니 신중하게 선택해야 한다. |
|||
| AWS GLUE 데이터 카탈로그 설정 | 이미지 |  |
하이브만 현재 메타 스토어를 사용하고 있어, 하이브만 선택한다. | |
| 설명 | 메타 데이터를 DB가 아닌 Glue 데이터 카탈로그를 사용시 다른 AWS 분석 서비스에 저장된 데이터를 쉽게 사용할 수 있으며, 어떻게 데이터가 변하였는지 모니터링 할 수도 있다. | |||
| 소프트웨어 설정 편집 | 이미지 |  |
기존 config 파일에서 커스텀 하였던 부분만 설정하면 될 것 같으며, 서버 스펙에 맞게 메모리나 디스크 사용량 조정, 저장 위치, replica 수 조정 이였기에 아마존 기본 설정을 보고 변경이 필요하다면 설정한다. 현재는 설정 하지 않으며, 만들어지고 기본 설정 보고 변경이 필요하면 수정한다. |
|
| 설명 | 하둡 각 서비스의 config 파일을 수정 할 수 있다. | |||
| 모든 단계 | 이미지 | 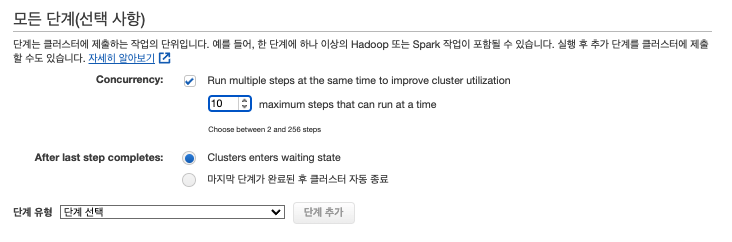 |
병렬로 실행하면 처리 속도가 빠르고, 운영중인 하둡도 병렬로 처리하고 있어 병렬 처리 선택한다. 자원 한도내에서 병렬 처리 했으나, 마스터 노드는 1대로 운영 하고 있어 마스터노드 메모리 한도를 확인하여 동시 실행 가능수를 제한한다. 운영중에 변경 가능하니 우선 max(256)개로 설정 하고 테스트를 통해 적정 수로 변경한다. 클러스터 사용시간이 정해져 있는 것이 아니므로 사용하지 않을시에 대한 동작은 대기 상태로 선택한다. 미리 단계를 추가하여 만들 수 있으나 구축한 뒤에도 실행 가능하니 우선 클러스터를 만드는것 부터 진행한다. |
|
| concurrency(동시성) | 클러스터에 제출하는 작업을 병렬로 실행 시킨다. 최대 256개 까지 실행, 보류 가능하며 동시 실행수는 설정 가능하다. |
|||
| After last step completes | 클러스터를 사용하지 않는다면 대기상태로 들어간다. | |||
| 마지막 단계가 완료된 후 클러스터 자동 종료 | 클러스터를 사용하지 않는다면 클러스터를 종료한다. | |||
| 단계 유형 | 클러스터 생성 시점에 단계를 추가하여 미리 만들어 둘 수 있다. | |||
| 2단계 : 하드웨어 | 클러스터 구성 | 이미지 |  |
저자의 경우 균일한 인스턴스 그룹을 선택하여 커스텀하게 조정 한다. |
| 균일한 인스턴스 그룹 | 임의로 설정 가능 | |||
| 인스턴스 플릿 | 최소한의 인스턴스 설정으로 대부분을 추천 대로 설정 (몇가지는 커스텀 가능) | |||
| 네트워킹 | 이미지 |  |
할당 받은 네트워크, 서브넷을 선택한다. 없다면 VPC 와 서브넷을 추가하고 온다. |
|
| 네트워크 | VPC(가상 네트워크)로 사용할 VPC 선택 | |||
| EC2 서브넷 | 사용할 IP 대역 선택 | |||
| 할당 전략 | 이미지 |  |
인스턴스 플릿 일때만 활성화 되는 화면으로 우리는 균일한 인스턴스 그룹을 사용하며 넘어간다. |
|
| 설명 | 가장 저렴한 구성으로 인스턴스가 할당 되도록 하는 옵션 | |||
| 클러스터 노드와 인스턴스 | 이미지 |  |
# 인스턴스 유형 M or T : 범용 인스턴스 C :컴퓨팅 최적화(고성능) R or X or Z : 메모리 최적화 P or G :가속화된 컴퓨팅 D or I :스토리지 최적화 - 인스턴스 유형 설명 : https://aws.amazon.com/ec2/instance-types/?nc1=h_ls M5 vs Ma5 M5는 인텔 CPU로 ma5보다 EBS 대역폭(Mbps)이 1.5배 정도 좋다. Ma5는 최대 대역폭이 m5보다 적지만 m5보다 가격이 저렴하다
|
|
| 노드 유형 | 마스터 : 마스터 노드 (= 네임노드) 코어 : 데이터 노드 작업 : 저장 공간은 없고 업무만 처리하는 노드 |
마스터 노드와 , 데이터 노드는 계속적으로 사용해야 하니 온디맨드로 설정하며, 작업 노드는 스팟 인스턴스로 설정 한다. 가격은 온디맨드 가격보다 저렴하면 되므로 '온디맨드를 최대 가격으로 사용'을 선택한다. 인스턴스 유형은 범용최신을 사용하며, 하둡은 JAVA 기반이므로 32G 를 넘게 사용할 경우 GC(Gabage Colection)가 발생할때 대기 시간이 길어질 수 있어 최대 32G로 설정한다. 마스터 노드는 1대 이므로 32G 로 설정 하고, 코어 노드는 기존 데이터 노드 수인 14대로 설정한다. 작업 노드는 어느정도 필요한지 몰라 코어 노드 수대로 지정하고 테스트를 통해 필요에 따라 조정한다. |
||
| 인스턴스 유형 | m : 범용 인스턴스 5 : 숫자가 클수록 최신 (4보다 가격 대비 성능이 좋다고 한다.) 2xlage : core, 메모리를 의미하며 편집 버튼을 눌러 확인 한다. EBS 스토리지 : 임시 파일 저장 공간 |
|||
| 인스턴스 수 | 인스턴스 수 | |||
| 구매 옵션 | 온디맨드 : 사용한 만큼 지불 스팟 : 최대 90% 저렴한 가격에 이용가능하나, 스팟 인스턴스는 쓰지 못하는 경우도 존재 하니 용도에 맞게 설정 한다. |
|||
| 클러스터 확장 | 이미지 |  |
|
|
| 확장 방식 | ||||
| EMR 관리형 확장 | 최저한의 : 최소 코어+작업 노드수 최고 : 최대 코어+작업 노드수 on-demand 제한 : 온디맨드 수 제한 최대 코어 노드 : 최대 코어 노드 수 제한 |
|||
| 자동 종료 | 이미지 |  |
종료 되면 임의로 시작해야 하므로 (자동시작은 없음) 활성화 하지 않는다. |
|
| 설명 | x시간 동안 사용 하지 않으면 자동으로 클러스터 종료하도록 설정 | |||
| EBS 루트 볼륨 | 이미지 |  |
||
| 설명 | 인스턴스 설정 정보, 인스턴스 정보가 담겨질 볼륨으로 인스턴스가 죽어도 영향 받지 않는 볼륨 | |||
| 3단계 : 일반 클러스터 설정 | 일반 클러스터 설정 | 이미지 | 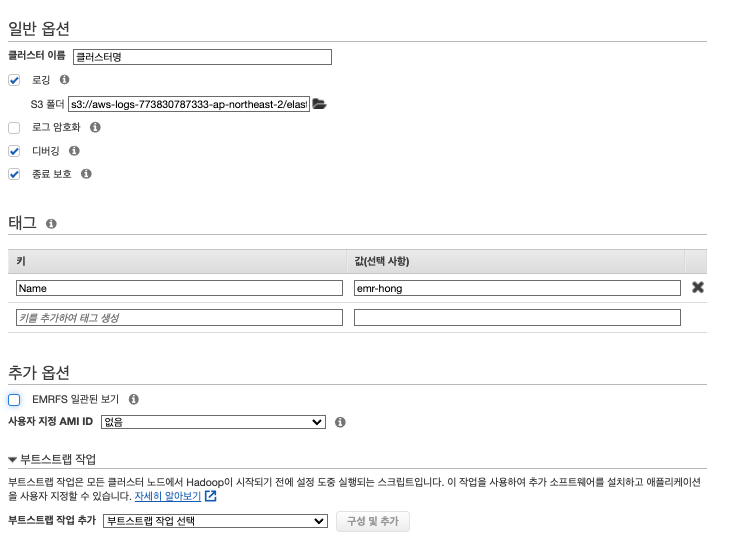 |
|
| 설명 | 로깅 마스터 노드에 저장된 로그 파일을 Amazon S3에 주기적으로 보관하도록 클러스터를 구성할 수 있습니다. 이렇게 하면 정상적인 종료를 통해서든 오류로 인해든 클러스터가 종료된 후 로그 파일을 사용할 수 있습니다. Amazon EMR은 5분 간격으로 로그 파일을 Amazon S3에 보관합니다. 로그 암호화 (나중에 s3, emr 모두 암호화 공부) . kms 암호화 가능 (key managerment service 사용 해야함) 디버깅 활성화 디버깅 도구를 사용하면 EMR 콘솔에서 로그 파일을 보다 쉽게 찾아볼 수 있습니다 종료 보호 스팟 인스턴스는 보호하지 않습니다 일관성 보기 EMR에서 S3에 데이터를 저장할 때 S3가 데이터 일관성을 지원하지 않기 때문에 같은 위치에 동시에 데이터를 쓰게 되면 데이터가 유실될 위험이 있습니다. 예를 들어 s3://[bucket]/a/b/c 위치에 한번에 100개 정도의 파일을 쓰게 되면 100개의 파일이 생성되지 않고, 파일이 유실되어 99개의 파일이 생성될 수 있습니다. >> Amazon S3가 강력한 쓰기 후 읽기 일관성을 지원하므로 더 이상 EMRFS 일관된 보기를 사용할 필요가 없습니다 사용자지정 ami 다른 ec2 구성으로 서버 구성시 사용 부트스트랩 작업 부트스트랩 작업은 모든 클러스터 노드에서 Hadoop이 시작되기 전에 설정 도중 실행되는 스크립트입니다. 이 작업을 사용하여 추가 소프트웨어를 설치하고 애플리케이션을 사용자 지정할 수 있습니다. 지금은 만들기 부터 |
|||
| 4단계 : 보안 | 보안 | 이미지 |  |
|
| 설명 | EC2 키 페어 - ec2 에 접속하기 위해 필요한 보안 키 파일 (.pem) 계정에 있는 모든 IAM 사용자가 볼 수 있는 클러스터 체크하여 다른 사용자도 해당 emr 클러스터를 볼수있도록 함 ec2 보안 그룹 -각 서비스별 방화벽 설정 선택 |
|||
| 키페어 추가 설명 | EC2 검색 > 키페어 클릭하여 접속 생성시 pem 파일이 생성되며 해당 파일로 서버를 접속한다. |
위에 설정 중에 S3 파일에 올려둔 설정 파일은 아래와 같으며 참고해서 설정 하며 공통적인 설정은 S3 에 저장하여 클러스터 구성시 불러와 자동으로 설정 적용 되도록 하는것이 운영하기 쉽다. (클러스터 일시 정지 기능이 없어 다시 구성하는 일이 많으므로)
[
{
"Classification": "hive-site",
"Properties": {
"hive.metastore.warehouse.dir": "s3a://emr-hong/data/warehouse"
}
},
{
"Classification": "oozie-site",
"Properties": {
"oozie.processing.timezone": "GMT+0900"
}
},
{
"Classification": "hdfs-site",
"Properties": {
"dfs.replication": "3"
}
}
]이제 설정을 마쳤다면 아래와 같이 클러스터 생성 버튼을 눌러 생성을 진행한다.
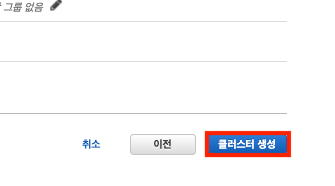
클러스터 생성이 된것을 볼 수 있다.

10분 정도 뒤에 모든 클러스터 구성이 완료 됐다.

끝!
'BIG DATA' 카테고리의 다른 글
| [AWS] EMR(hadoop) - 배치를 만들어보자! (0) | 2022.01.30 |
|---|---|
| [AWS] EMR(hadoop) - 기본적인 부분을 알아보자! (0) | 2022.01.29 |
| [AWS] 보안 (ACL vs Security Group) (0) | 2022.01.29 |
| [AWS] S3 생성 (저장소 생성) (0) | 2022.01.29 |
| [AWS] EC2를 이용한 KAFKA Connect 구축 (0) | 2022.01.17 |



