
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- java
- Redis
- spring
- hive
- 젠킨스
- EMR
- 레디스
- Zeppelin
- fastcampus
- 자바
- ec2
- Docker
- 클러스터
- vue
- config
- 로그인
- 예제
- Mac
- Kafka
- 자동
- 설정
- 머신러닝
- Cluster
- login
- 간단
- Jenkins
- redash
- SpringBoot
- gradle
- aws
- Today
- Total
코알못
[문자인코딩] 02) 문자 인코딩/디코딩 실습 본문

우선 실습에 앞서 프로젝트를 생성해보자!
아래 화면과 같이 자바 프로젝트를 생성하며 자바 21버전을 사용하도록 한다.

프로젝트 생성시 Add sample code 에 체크박스 했기 때문에
아래와 같이 예제 코드가 들어있다.
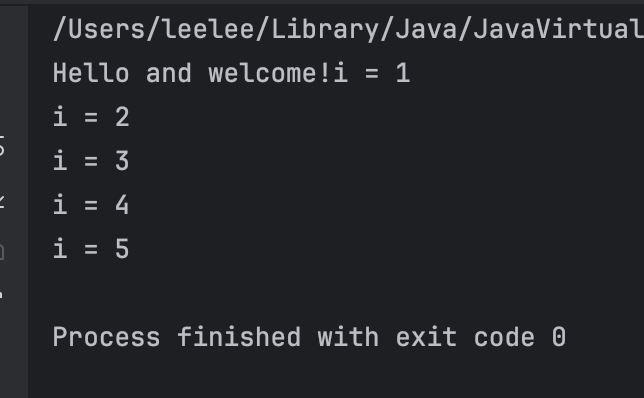
메인을 실행하여 동작 여부를 확인해보자!

결과를 보면 정상적으로 출력 되는것을 볼 수 있다.
이제 메인 클래스에 아래와 같이 코드를 작성해보자!
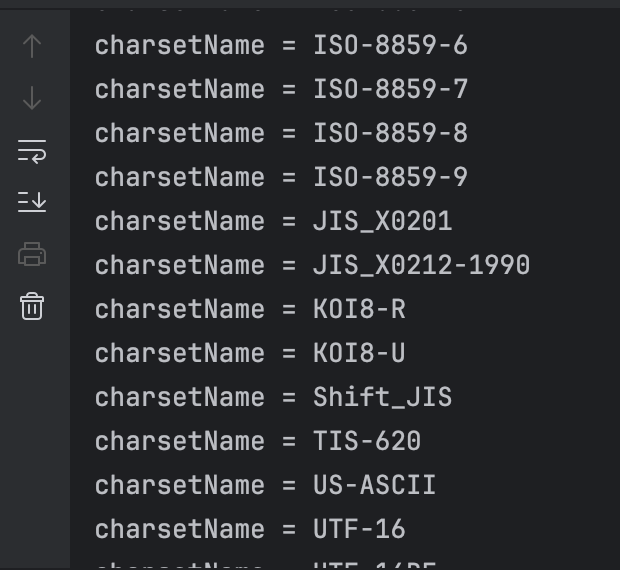
해당 코드는 현재 이용 가능한 모든 문자 집합을 조회하는 코드이다.
// 이용 가능한 모든 Charset 자바 + OS
SortedMap<String,Charset> charsets = Charset.availableCharsets();
for (String charsetName : charsets.keySet()) {
System.out.println("charsetName = " + charsetName);
}메인을 실행하여 확인해보면 정말 많은 문자 집합이 나오는것을 볼 수 있다.
문자 집합을 사용하고 싶을경우 이와 같이 확인하여 지원 하는지 확인해 볼 수 있다.
다음으로 MS949 문자 집합을 조회해보자!
// 문자로 조회
Charset charset = Charset.forName("MS949");
System.out.println("charset = " + charset);지원하는 항목에 있었기 때문에 아래와 같이 정상 출력 된다.
그러나 ms949 가 아닌 처음 보는 명칭이 나왔다!
출력된 명칭이 본 명칭이며 ms949는 별칭이다.
우리가 forName 에 별칭을 대소문자 구분 없이 입력하면 해당하는 문자 집합을 가져올 수 있다!

그럼 입력 가능한 별칭은 무엇이 있을까?
아래와 같이 해당 하는 문자 집합의 별칭을 조회 해 볼 수 있다.
// 별칭 조회
Charset charset = Charset.forName("MS949");
Set<String> aliases = charset.aliases();
for (String alias : aliases) {
System.out.println("alias = " + alias);
}결과를 보면 우리가 사용한 ms949 별칭을 포함하여 다른 별칭도 확인 할 수 있다.

Charset.forName 으로 별칭을 입력하여 문자 집합을 가져 올 수 있지만
자주 사용되는 문자 집합은 상수로 제공하고 있다.
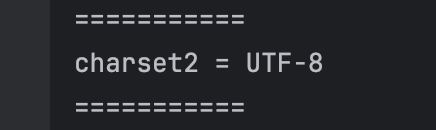
UTF-8 의 경우 아래와 같이 SrandardCharsets 으로 제공하는 상수를 사용하여 문자 집합을 바로 가져올 수 있다.
// 자주 사용하는 문자집합은 상수로 제공
Charset charset2 = StandardCharsets.UTF_8;
System.out.println("charset2 = " + charset2);출력을 보면 정상적으로 가져온것을 알 수 있다.
이제 우리 시스템인 OS 에 설정된 문자 집합을 조회해보자!
// 시스템의 기본 Charset 조회
Charset charset3 = Charset.defaultCharset();
System.out.println("charset3 = " + charset3);저자의 경우 UTF-8 로 설정 되어있는것을 볼 수 있다.
사용자 PC 마다 설정 값이 다르므로 저자와 출력은 다를 수 있다.

이제 실제로 문자 집합을 이용하여 인코딩 하는 실습을 해보자!
아래와 같이 미리 문자 집합을 상수로 지정해둔다.
그리고 encoding 메서드를 만들어 인코딩 되는 값을 출력, 몇바이트를 사용했는지 출력되도록 한다.
String.getByte 에 문자 집합을 변수로 넣으면 해당 문자집합으로 인코딩 된다.
그리고 main 함수에서 A 와 a 가 ASCII 인코딩 했을시 출력이 어떻게 되는지 확인해보자!
private static final Charset EUC_KR = Charset.forName("EUC-KR");
private static final Charset MS_949 = Charset.forName("MS949");
public static final Charset US_ASCII = StandardCharsets.US_ASCII;
public static void main(String[] args) {
System.out.println("== ASCII 영문 처리 ==");
encoding("A", US_ASCII);
encoding("a", US_ASCII);
}
private static void encoding(String text, Charset charset) {
byte[] bytes = text.getBytes(charset);
System.out.printf("%s -> [%s] 인코딩 -> %s %sbyte\n", text, charset, Arrays.toString(bytes), bytes.length);
}main 을 돌려보면 아래와 같이 나온다.
A 의 경우 ASCII 로 인코딩시 65 이며 1byte를 사용한다.
a 의 경우 97이다.
저번 시간에 배운대로 정상적으로 인코딩 되어 출력 되었다.

이제 동일한 A 문자를 가지고 여러 문자 집합별 결과가 어떻게 나오는지 확인해보자!
public static final Charset UTF_8 = StandardCharsets.UTF_8;
private static final Charset EUC_KR = Charset.forName("EUC-KR");
private static final Charset MS_949 = Charset.forName("MS949");
public static final Charset US_ASCII = StandardCharsets.US_ASCII;
public static final Charset ISO_88591 = StandardCharsets.ISO_8859_1;
public static final Charset UTF_16BE = Charset.forName("UTF-16BE");
public static void main(String[] args) {
System.out.println("== ASCII 영문 처리 ==");
encoding("A", US_ASCII);
encoding("A", ISO_88591);
encoding("A", EUC_KR);
encoding("A", UTF_8);
encoding("A", UTF_16BE);
}
private static void encoding(String text, Charset charset) {
byte[] bytes = text.getBytes(charset);
System.out.printf("%s -> [%s] 인코딩 -> %s %sbyte\n", text, charset, Arrays.toString(bytes), bytes.length);
}결과를 확인해보면..
영문은 US-ASCII, ISO-8859-1, EUC-KR, MS949, UTF-8 모두 ASCII 와 호환된다.
해당 문자 집합들은 1byte 만 사용하고 숫자 65로 인코딩 한다.
그러나 UTF-16의 경우 ASCII 와 호환되지 않는다.
그 이유는 결과를 보면 2byte 를 사용하고 숫자 0, 65 로 인코딩 되어 이전 인코딩과는 다른값으로 인코딩 되기 때문이다.

이제 한글 인코딩을 테스트 해보자!
public static final Charset UTF_8 = StandardCharsets.UTF_8;
private static final Charset EUC_KR = Charset.forName("EUC-KR");
private static final Charset MS_949 = Charset.forName("MS949");
public static final Charset US_ASCII = StandardCharsets.US_ASCII;
public static final Charset ISO_88591 = StandardCharsets.ISO_8859_1;
public static final Charset UTF_16BE = Charset.forName("UTF-16BE");
public static void main(String[] args) {
System.out.println("== 한글 지원 ==");
encoding("가", EUC_KR);
encoding("가", MS_949);
encoding("가", UTF_8);
encoding("가", UTF_16BE); // UTF-16 문자 집합 표기법중 BE, LE 가 있는데 의미하는 바는 인코딩 숫자 표기 되는 순서일뿐 두개는 같다.
}
private static void encoding(String text, Charset charset) {
byte[] bytes = text.getBytes(charset);
System.out.printf("%s -> [%s] 인코딩 -> %s %sbyte\n", text, charset, Arrays.toString(bytes), bytes.length);
}한글의 경우 EUC-KR, MS949 는 동일하게 2byte 를 사용하며 인코딩 된 값도 동일하다.
그러므로 서로 호환 되는것을 알 수 있다.
저번 시간에 MS949 는 EUC-KR 확장 버전이라고 배웠으며 그렇기 때문에 결과도 동일 하게 된다.
그러나 UTF-8 의 경우 한글 인코딩은 3byte 를 사용하므로 다르게 인코딩 된것을 볼 수 있으며
UTF-16 의 경우에는 2byte 를 사용하나 인코딩 된 값이 다르므로 호환 되지 않는다.

문자를 byte 로 변경하려면 무조건 문자 집합이 필요하다.
그래서 String.getByte() 인자로 Charset 문자집합을 넘겨줘야 한다.
넘겨주지 않을시 시스템 기본 문자집합을 인코딩에 사용한다는 점을 알 고 있어야 한다.
이제 인코딩 > 디코딩 테스트를 해보도록 하자!
아래와 같이 코드 작성하면 되며
test 메서드에서 String.getByte(문자집합) 을 통해 해당 문자집합으로 인코딩 하며
new String(인코딩 byte, 문자집합) 을 통해 해당 문자 집합으로 디코딩 한다.
인코딩, 디코딩 할때는 반드시 문자집합을 지정해줘야 하며 지정 안할 시 시스템 default 설정을 따르게 되므로
실무에서는 시스템 마다 결과가 달라지지 않도록 지정 해주도록 하자!
그리고 main 함수에서 'A' 를 ASCII 로 인코딩 하고 다른 문자 집합으로 디코딩 했을때 결과를 보도록 하자!
public static final Charset ISO_88591 = StandardCharsets.ISO_8859_1;
public static final Charset UTF_8 = StandardCharsets.UTF_8;
private static final Charset EUC_KR = Charset.forName("EUC-KR");
private static final Charset MS_949 = Charset.forName("MS949");
public static final Charset US_ASCII = StandardCharsets.US_ASCII;
public static final Charset UTF_16_BE = StandardCharsets.UTF_16BE;
public static void main(String[] args) {
System.out.println("== 영문 ASCII 인코딩 ==");
test("A", US_ASCII, US_ASCII);
test("A", US_ASCII, ISO_88591);
test("A", US_ASCII, EUC_KR);
test("A", US_ASCII, MS_949);
test("A", US_ASCII, UTF_8);
test("A", US_ASCII, UTF_16_BE);
}
private static void test(String text, Charset encodingCharset, Charset decodingCharset) {
byte[] encoded = text.getBytes(encodingCharset);
String decoded = new String(encoded, decodingCharset);
System.out.printf("%s -> [%s] 인코딩 -> %s %sbyte -> [%s] 디코딩 -> %s\n", text, encodingCharset, Arrays.toString(encoded), encoded.length, decodingCharset, decoded);
}
결과를 보면 UTF-16 빼고는 모두 ASCII 를 호환 하기 때문에 정상적으로 나오며
UTF-16은 지원하지 않기 때문에 '?' 로 나오는것을 볼 수있다.

이제 한글 인코딩 테스트 해보도록 하자!
System.out.println("== 한글 인코딩 ==");
test("가", US_ASCII, US_ASCII);
test("가", ISO_88591, ISO_88591);
test("가", EUC_KR, EUC_KR);
test("가", MS_949, MS_949);
test("가", UTF_8, UTF_8);
test("가", UTF_16_BE, UTF_16_BE);ASCII , ISO-8859의 경우에는 한글 지원 하지 않기 때문에 ? 로 나왔으며
나머지는 한글 지원하므로 정상적으로 인코딩, 디코딩이 되는것을 볼 수 있다.

이제 복잡한 한글인 '뷁'을 인코딩 해보자!
System.out.println("== 한글 인코딩 - 복잡한 문자 ==");
test("뷁", EUC_KR, EUC_KR);
test("뷁", MS_949, MS_949);
test("뷁", UTF_8, UTF_8);
test("뷁", UTF_16_BE, UTF_16_BE);저번 시간에 배운 내용과 같이 EUC-KR 은 자주사용하는 한글만 표기 되도록 집합이 구성되어있어 '뷁'은 문자 집합에 없다.
그래서 ? 로 나오는것을 볼 수 있다.
그리고 EUC-KR 의 확장 버전인 MS-949와 그 뒤에 나온 UTF-8, 16 모두 정상적으로 인코딩, 디코딩 되는것을 볼 수있다.

이제 한글 인코딩과 디코딩이 다른경우를 보자!
System.out.println("== 한글 인코딩 - 디코딩이 다른경우 ==");
test("가", EUC_KR, MS_949);
test("뷁", MS_949, EUC_KR);
test("가", MS_949, UTF_8);
test("가", UTF_8, MS_949);결과를 보면..
'가' 의 경우 EUC-KR, MS949 모두 지원하므로 정상 인코딩, 디코딩 되어 출력 된것을 볼 수 있다.
그러나 '뷁' 의 경우 EUC_KR 에서 지원하지 않기 떄문에 인코딩은 정상적으로 됐을지라도 디코딩에서 실패하여 '?' 로 노출된다.
그리고 MS949 와 UTF-8 은 한글 인코딩 되는 byte 수 부터 다르기 때문에 ? 로 나오게 된다.

영문의 경우에도 보자!
System.out.println("== 영문 인코딩 - 디코딩이 다른경우 ==");
test("A", EUC_KR, UTF_8);
test("A", MS_949, UTF_8);
test("A", UTF_8, MS_949);
test("A", UTF_8, UTF_16_BE);영문의 경우 모두 1byte 로 인코딩 되며 모두 호환 되지만, UTF-16 의 경우 2byte 로 인코딩 값이 다르다.
그러므로 UTF-16 으로 디코딩 한 부분만 ? 로 나오는것을 볼 수 있다.

이제 총 정리 해보자!
영문은 대부분 모두 호환 되나 UTF-16 은 호환 되지 않아 인코딩/디코딩시 오류 발생 한다.
한글의 경우 EUC-KR 과 MS949 는 호환 되나 '뷁' 같이 자주 사용하지 않는 한글은 EUC-KR 에서는 문자 집합이 없기에 오류 발생할 수 있다.
그 외 한글 인코딩/디코딩을 다른 문자 집합으로 할때 서로 호환 되지 않아 오류 발생 할 수 있다.
# 참고
1) byte 출력에 - 가 나오는 이유는 ?
1byte 는 8bit 로 256 가지 표현된다. 그러나 자바에서 byte 는 양수, 음수 모두 표현 가능하다.
그러므로 십진수로 표기 할때 256 가지 이지만 -128 ~ 127 로 표기 한다.
메모리에 이진수로 저장되는 값은 같으나 화면에 십진수에 표기 되는거만 다른것 뿐이다.
'JAVA' 카테고리의 다른 글
| [문자인코딩] 01) 문자 인코딩이란? (1) | 2026.03.16 |
|---|---|
| [TDD] SpringBoot 를 통한 TDD 손쉬운 작성 - 05) 테스트 코드 품질 높이기! - 03 (0) | 2026.03.10 |
| [TDD] SpringBoot 를 통한 TDD 손쉬운 작성 - 04) 테스트 코드 품질 높이기! - 02 (0) | 2026.03.08 |
| [TDD] SpringBoot 를 통한 TDD 손쉬운 작성 - 03) 테스트 코드 품질 높이기! - 01 (1) | 2026.03.02 |
| [TDD] SpringBoot 를 통한 TDD 손쉬운 작성 - 02) TDD 작성 해보기! (0) | 2026.03.01 |



