
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 머신러닝
- 자바
- 설정
- EMR
- Zeppelin
- 예제
- 자동
- config
- Redis
- java
- Jenkins
- 클러스터
- gradle
- vue
- 간단
- hive
- ec2
- 젠킨스
- fastcampus
- spring
- Docker
- SpringBoot
- 레디스
- 로그인
- login
- Kafka
- redash
- aws
- Cluster
- Mac
- Today
- Total
코알못
[코테] 시간/공간 복잡도 본문
시간/공간 복잡도란?
시간 복잡도는 알고리즘이 실행되는데 걸리는 시간/사용되는 공간을 수학적으로 표현한 개념입니다. 입력 크기 N이 커질수록 얼마나 많은 연산이 수행되는지를 알려주기 때문에, 알고리즘의 성능 비교에 유용 합니다.
시간 복잡도 계산법
📌 예제 코드로 살펴보기
아래 코드는 리스트 안에서 가장 큰 숫자를 찾는 간단한 함수입니다:
def find_max_num(array):
for number in array:
is_max_num = True
for compare_number in array:
if number < compare_number:
is_max_num = False
if is_max_num:
return number
이 코드를 기준으로, 각 부분이 얼마나 많은 연산을 수행하는지 분석해보겠습니다.
🔍 안쪽의 is_max_num = False 까지 걸리는 시간
for number in array:
for compare_number in array:
if number < compare_number:
is_max_num = False- array의 길이가 N이라고 할 때,
- 첫번째 for문은 N번 반복됩니다.
- 두번째 for문도 N번 반복됩니다.
- 반복 안에서는 조건문 if와 대입문 is_max_num = False가 각각 1번씩 실행되므로, 1 + 1 = 2번의 연산이 매 반복마다 일어납니다.
👉 총 연산 수:
N * N * 2 = 2N^2
🔍 그 다음 if is_max_num: 의 시간
for number in array:
if is_max_num:
return number- 이 부분은 바깥 루프가 한 번씩 돌 때마다 실행 가능성이 있으므로,
- 최대 N번 실행된다고 볼 수 있고, 조건문 하나만 있으니
👉 총 연산 수:
N * 1
📊 최종 시간 복잡도
앞서 계산한 두 개를 합치면:
2N^2 + N
하지만 시간 복잡도는 대략적인 성능 비교용이기 때문에, 가장 영향이 큰 항만 남기고 나머지는 생략합니다.
👉 따라서 최종 시간 복잡도는:
여기서 잠깐!
가끔 시간 복잡도를 계산하다 보면, 다음과 같이 상수값이 나오는 경우가 있습니다.
예를 들어 어떤 알고리즘이 항상 정확히 26번의 연산만 수행된다고 해봅시다. 그러면 이 알고리즘의 시간 복잡도는 26이라고 말할 수 있겠지만 사실 시간 복잡도에서는 이런 상수값은 중요하지 않습니다.
시간 복잡도는 입력 크기 N이 커질수록 알고리즘의 성능이 어떻게 변하는지를 보는 것이지, 정확한 실행 횟수 자체를 따지는 게 아니기 때문입니다.
즉,
"26이나 1이나 결국은 항이 따로 없고 입력 크기에 따라 변하지 않기 때문에, 시간 복잡도는 "
🗃️ 공간 복잡도 계산법
시간 복잡도와 함께 알고리즘을 평가할 때 꼭 함께 고려해야 할 것이 공간 복잡도입니다.
공간 복잡도는 문제를 해결하는 데 얼마나 많은 메모리(공간)를 사용하는지를 나타냅니다.
당연히 필요한 공간을 적게 쓸수록 더 효율적인 알고리즘이라고 볼 수 있습니다.
📌 예제 코드로 살펴보기
이 코드를 기준으로 어떤 공간들이 사용되었는지 살펴보겠습니다.
def find_max_occurred_alphabet(string):
alphabet_occurrence_array = [0] * 26
for char in string:
if not char.isalpha():
continue
arr_index = ord(char) - ord('a')
alphabet_occurrence_array[arr_index] += 1
max_occurrence = 0
max_alphabet_index = 0
for index in range(len(alphabet_occurrence_array)):
alphabet_occurrence = alphabet_occurrence_array[index]
if alphabet_occurrence > max_occurrence:
max_occurrence = alphabet_occurrence
max_alphabet_index = index
return chr(max_alphabet_index + ord('a'))📦 사용된 메모리 분석
- alphabet_occurrence_array → 26개의 공간 사용 (알파벳 개수)
- arr_index → 1개
- max_occurrence, max_alphabet_index, alphabet_occurrence → 각각 1개씩, 총 3개
👉 전체 공간 사용량은
26 + 1 + 3 = 30 이 됩니다.
📊 최종 공간 복잡도
이론적으로는 30이지만, 입력 크기와 무관하게 고정된 수만큼의 공간만 사용하는 경우, 공간 복잡도는 상수로 봅니다.
즉,
"입력에 따라 메모리 사용량이 늘어나지 않기 때문에, 이 알고리즘의 공간 복잡도는 1 입니다."
이처럼 시간 복잡도와 공간 복잡도를 함께 고려해서 계산하면, 보다 효율적이고 현실적인 알고리즘을 설계할 수 있습니다.
그렇다면 이 복잡도들을 어떻게 표기할까요?
점근 표기법
복잡도는 보통 수학적인 기호로 표현하는데, 이를 점근 표기법이라고 합니다.
가장 대표적인 표기법은 다음과 같습니다:
| (빅 오) | 최악의 경우에 필요한 연산량 또는 공간 |
| (빅 오메가) | 최선의 경우에 필요한 연산량 또는 공간 |
❗ 왜 빅오(Big-O) 표기법을 주로 사용할까?
현실에서는 입력값이 언제나 좋게 들어온다는 보장이 없기 때문입니다.
즉, 우리는 최악의 상황에서도 알고리즘이 어느 정도 성능을 유지할 수 있어야 하고, 이를 위해 빅오 표기법을 기준으로 평가합니다.
복잡도 표기 예시
복잡도를 점근 표기법으로 표현할 때는 다음과 같이 작성합니다:
- 시간 복잡도가 N^2이라면 →
- 공간 복잡도가 1이라면 → O(1)
이처럼 시간과 공간 복잡도는 각각 독립적으로 계산하고, 점근 표기법(Big-O)을 사용해 간단하게 표현합니다.
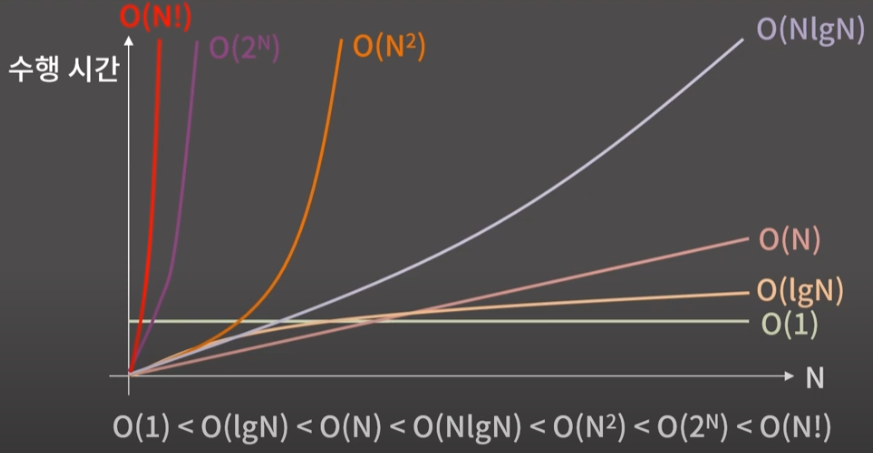
각 시간 복잡도는 위 그림과 같이 비교 할 수 있으며 이를 참고하여 다음 시간 부터 알고리즘을 풀어보도록 하자!
'ETC' 카테고리의 다른 글
| [코테] 재귀함수 (0) | 2025.04.20 |
|---|---|
| [코테] 이진 탐색 (1) | 2025.04.20 |
| Tomcat, Intellij, Gradle 관련 기본 내용 정리 (0) | 2025.02.10 |
| [pyspark] UNSUPPORTED_SUBQUERY_EXPRESSION_CATEGORY (0) | 2023.09.14 |
| [kubernetes] Ingress - IngressController 설치 (0) | 2023.09.10 |

