
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 자동
- hive
- 간단
- config
- vue
- Zeppelin
- 레디스
- 로그인
- Docker
- Jenkins
- EMR
- 머신러닝
- Redis
- redash
- gradle
- login
- 젠킨스
- SpringBoot
- 예제
- spring
- aws
- 설정
- fastcampus
- 자바
- Cluster
- ec2
- java
- 클러스터
- Kafka
- Mac
- Today
- Total
코알못
[HIVE] UDF(User Defined Function) 생성 및 마스킹 적용 본문
hive 사용자 정의 함수 생성 방법에는 두가지 방법이 있다.
- UDF(org.apache.hadoop.hive.ql.exec.UDF) 상속
- evaluate() 함수 구현
- GenericUDF(org.apache.hadoop.hive.ql.udf.generic.GenericUDF) 상속
- initialize(), evaluate(), getDisplayString() 함수를 구현
간단한 방법은 UDF이나 현재 deprecated 되어 GenericUDF로 구현하도록 한다!
우선 위에 필수로 구현해야하는 함수를 설명하면
initialize 함수는 입력 매개변수에 대한 값 체크하는 로직 작성하는 함수이며 조건에 맞지 않을시 Exception을 발생시키면 쿼리 오류 발생하며 정의한 메세지를 노출 시킨다.
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
}evaluate 함수는 실제 동작할 내용을 구현하면 된다.
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException{
}getDisplayString 함수는 필수로 Override 해야하나 어떤 역할을 하는지 파악중에 있다. 저자의 경우 현재까지 사용하는데 정의가 필요한 부분이 없었다.
@Override
public String getDisplayString(String[] errInfo) {
}최종적으로 완성된 코드는 아래에서 확인하면 된다.
https://github.com/works-code/hive-udf
GitHub - works-code/hive-udf: hive-udf
hive-udf. Contribute to works-code/hive-udf development by creating an account on GitHub.
github.com
이제 사용자 정의 함수를 사용하기 위해 하둡에 업로드할 디렉토리 생성하고 위에 코드로 빌드하여 만든 라이브러리 명을 변경한다.
$ hadoop fs -mkdir /user/hive/lib/
$ mv hive-udf-0.0.1-SNAPSHOT-plain.jar hive-udf-0.0.1.jar아래 명령어를 통해 hdfs 또는 s3에 올린다.
$ aws s3 cp hive-udf-0.0.1.jar s3://.../lib/
or
$ hadoop fs -put hive-udf-0.0.1.jar /user/hive/lib/hive 에 접속하여 jar 파일을 hdfs 또는 s3 경로에서 가져온다.
$ hive
hive> ADD JAR hdfs://[master host dns]/user/hive/lib/hive-udf-0.0.1.jar;
hive> CREATE TEMPORARY FUNCTION encrypt AS 'com.hive.udf.function.Encrypt';
or
hive> CREATE TEMPORARY FUNCTION encrypt AS 'com.hive.udf.function.Encrypt' USING JAR 's3://.../lib/hive-udf-0.0.1.jar';hive에 접속 하여 테스트 테이블 및 데이터를 생성한다.
$ hive
hive> use genie_test;
hive> CREATE TABLE tb_test(
data string
);
hive> INSERT INTO tb_test VALUES("test01");
hive> INSERT INTO tb_test VALUES("test02");
hive> select * from tb_test;
OK
test01
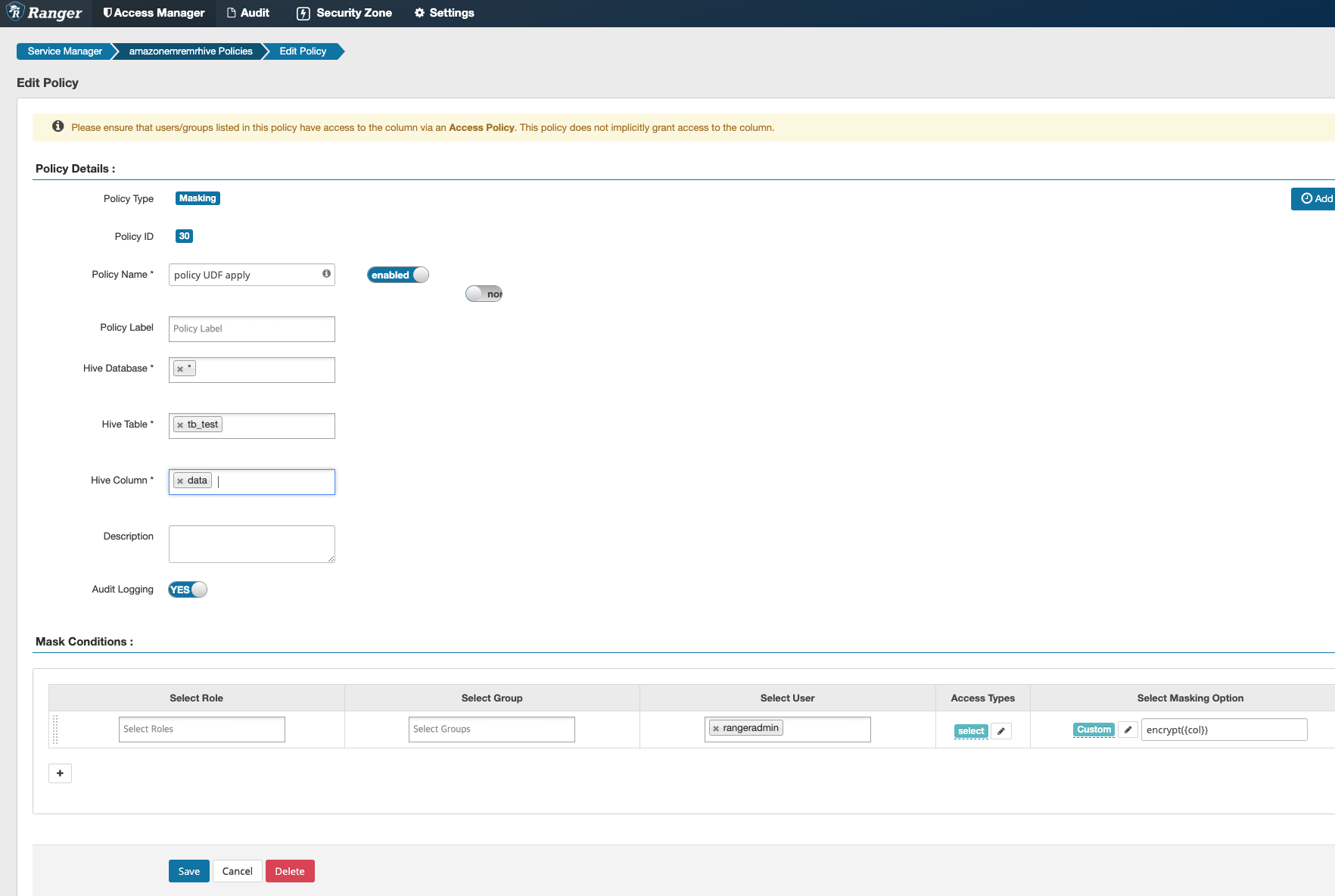
test02이제 ranger를 이용하여 생성한 테이블의 data 칼럼에 사용자 함수로 마스킹 적용을 해보자!

아래와 같이 설정하며 칼럼의 경우 '{col}' 이라고 기재하면 된다.
ranger가 적용된 EMR hive에 들어가서 다시 조회해보면
$ kinit rangeradmin
Password for rangeradmin@COMPUTE.INTERNAL:
$ beeline
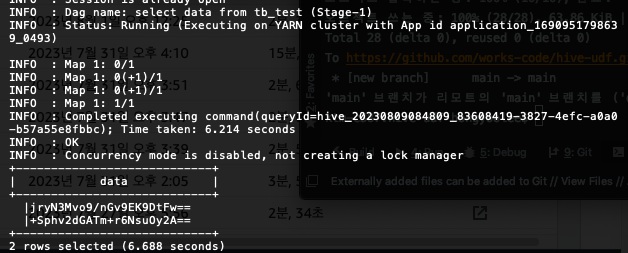
beeline>!connect jdbc:hive2://[master ip]:10000/;principal=hive/[master DNS]@COMPUTE.INTERNAL
0: jdbc:hive2://[master ip]:10000/> select data from tb_test;사용자 정의 함수로 암호화 된것을 볼 수 있다.
끝!
# 오류 케이스
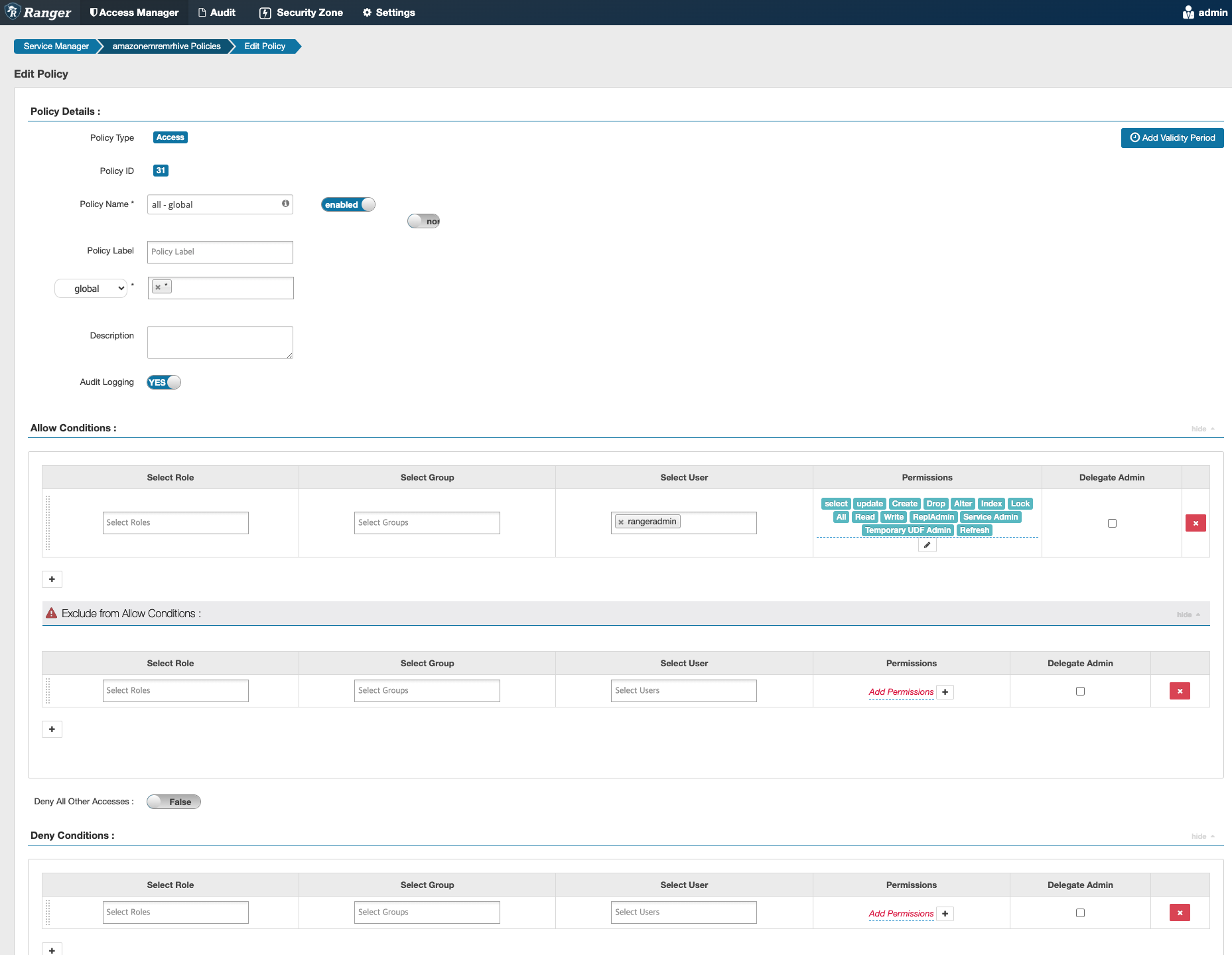
0: jdbc:hive2://IP:10000/> add jar s3://../lib/hive-udf-0.0.1.jar;
Error: Error while processing statement: Permission denied: user [rangeradmin] does not have [TEMPUDFADMIN] privilege on [global] (state=,code=1)해결방안은 아래와 같이 global 관련 권한 허용한다.
'BIG DATA' 카테고리의 다른 글
| [HIVE] 메타스토어 직접 접속해서 테이블 정보 확인 및 수정 (0) | 2023.09.11 |
|---|---|
| [Spark] 잡 종료되는 이슈 대응을 위한 옵션 튜닝 (0) | 2023.04.03 |
| [Spark] ExecutorLostFailure, RuntimeException (0) | 2023.03.20 |
| [EMR] Zeppelin python 버전 변경 (0) | 2023.02.22 |
| [Kubernetes & Docker] Kuberneties 구성 (0) | 2023.02.09 |


