
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 머신러닝
- SpringBoot
- gradle
- 로그인
- Docker
- java
- vue
- 설정
- 클러스터
- 레디스
- 간단
- ec2
- Cluster
- 젠킨스
- Jenkins
- Mac
- Zeppelin
- fastcampus
- hive
- redash
- 자동
- config
- aws
- spring
- Kafka
- Redis
- EMR
- 자바
- 예제
- login
- Today
- Total
코알못
[EMR] Glue > Aurora Metastore Migration 본문

EMR Glue Metastore 이용하고 있었으나
Ranger 플러그인 활성화한 EMR 사용시에는 AWS 에서 Glue 를 지원하지 않는다고 한다.
이미 Glue 에 많은 메타 정보가 담아둔 상태로 수동으로 직접 스키마를 옮기는것은 힘들다고 판단하였다.
찾아보던중 AWS 에서 제공하는 glue 마이그레이션 샘플 스크립트가 있었으며
AWS 에서 공식으로 지원하는 스크립트는 아니라고 하니 본인 구성에 맞게 수정하여 사용한다.
만약 적은 데이터가 있다면 직접 옮기는게 빠를 수 있으니
아래 명령어로 테이블 생성 스크립트를 가져와서 생성하면 되며
// glue 연동된 hive
hive> show create table [테이블명]아래 명령어로 파티션 정보도 확인 가능하다.
// 생성된 파티션 보기
hive> show partitions [테이블명];
// 파티션 location 확인
hive -e "explain extended select * from {DB}.{TABLE}" | grep location이제 glue 에서 AWS aurora 로 이관해보자! (aurora 가 아니고 외부 DB 나 RDS 도 동일한 방법으로 가능하다.)
- AWS Migration Sample Git : https://github.com/aws-samples/aws-glue-samples/tree/master/utilities/Hive_metastore_migration
GitHub - aws-samples/aws-glue-samples: AWS Glue code samples
AWS Glue code samples. Contribute to aws-samples/aws-glue-samples development by creating an account on GitHub.
github.com
여기서 'Migrate Directly from AWS Glue to Hive' 또는 'Migrate from AWS Glue to Hive through Amazon S3 Objects' 를 보고 진행 하면 되며 저자의 경우 후자를 통해 마이그레이션 작업을 진행하였으며 과정은 아래와 같다.
[1] Glue 메타 데이터 > S3로 이관
[2] S3 > 메타 스토어로 지정한 DB 에 최종 이관
[1] Glue 메타 데이터 > S3로 이관 부터 진행한다.
우선 아래 2개의 파일을 사용할 것이며 그 중 2번만 S3 에 업로드 한다.
1. export_from_datacatalog.py
2. hive_metastore_migration.py
그 다음 Glue ETL 서비스인 Glue Studio Job 을 생성하여 해당 스크립트를 돌릴 것이다.
우선 Glue Studio 를 사용하기 위해 IAM 권한 설정 작업이 필요하다.
:: https://docs.aws.amazon.com/ko_kr/glue/latest/dg/getting-started-access.html
AWS Glue에 대한 IAM 권한 설정 - AWS Glue
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
총 3단계 작업을 진행하면 된다.
1단계 : AWS Glue 서비스를 위한 IAM 정책 생성
우선 Glue 가 사용할 정책을 만들어야 하나 만들지 않고 AWS 에서 만들어둔 정책인 'AWS 관리형 정책 AWSGlueServiceRole' 을 사용해도 된다. (저자도 관리형 정책을 사용할 예정으로 이부분은 패스했다.)
2단계 : AWS Glue에 대한 IAM 역할 생성
아래와 같이 Glue Studio 에서 Job 을 생성할시 사용할 역할을 선택하여 Glue 서비스가 정책을 할당 받도록 하는데 여기서 사용할 역할이다.

IAM > 역할(Roles) > 역할 생성(Create role)

Glue 가 S3에 접근할 수 있어야 하므로(파일을 생성하거나 로그를 남기는데 사용) 아래와 같이 S3 Full Access 정책에 대해 검색하여 체크 박스 선택한다.

그리고 1단계에서 정책을 생성 하였다면 생성한 정책명을 검색하고, 그게 아니라면 'AWSGlueServiceRole' 을 검색하고
체크 박스 선택하여 Next 누른다.

마지막으로 역할명을 기재하고 생성한다.
참고사항으로
역할명이 'AWSGlueServiceRole' 로 시작하면 PassRole 권한을 따로 주지 않아도 되나 만약 역할명을 다르게 준다면
Glue Studio Service 에게 역할에 대한 사용 권한을 넘겨줄 수 있도록 사용자에게 PassRole 을 부여해야 한다.
그 방법은 아래와 같으며 두개 중 원하는 정책을 연결한다. (역할명이 'AWSGlueServiceRole' 로 시작 하도록 만들었다면 아래 과정은 패스해도 된다.)
- IAM > Users > 해당 사용자 클릭 > Permissions 탭 클릭 > Add permissions > Create Inline policy
// Glue Studio Service 한정 PassRole 부여
Region name 은 서울이면 'ap-northeast-2' 이다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::[Account ID]:role/[Role Name]",
"Condition": {
"StringEquals": {"iam:PassedToService": "gluestudio-service.[Region name].amazonaws.com"}
}
}
]
}// 모든 서비스에 PassRole 부여
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::[Account ID]:role/[Role Name]"
}
]
}3단계: AWS Glue에 액세스하는 IAM 사용자에게 정책 연결
그리고 사용자가 Glue Console 을 사용할 수 있도록
'AWS 관리형 정책 AWSGlueConsoleFullAccess' 연결하거나 인라인 정책을 생성하여 연결 한다.
1. AWSGlueConsoleFullAccess' 연결
- IAM > Users > 해당 사용자 클릭 > Permissions 탭 클릭 > Add permissions > Attach policy > 'AWSGlueConsoleFullAccess' 선택
2. 직접 정책 생성
- IAM > Users > 해당 사용자 클릭 > Permissions 탭 클릭 > Add permissions > Create Inline policy > 정책 입력
이제 Glue 사용할 준비가 완료 되었으며
아래와 같이 AWS 콘솔에서 Glue Studio 를 검색하여 들어간다.

view jobs 를 클릭하고 아래와 같이 선택한다.
- 'spark script editor' > 'Choose file' > 로컬 PC 에서 'export_from_datacatalog.py' 선택 > 'Create' 클릭

아래와 같이 스크립트가 업로드 된것을 볼 수 있다.

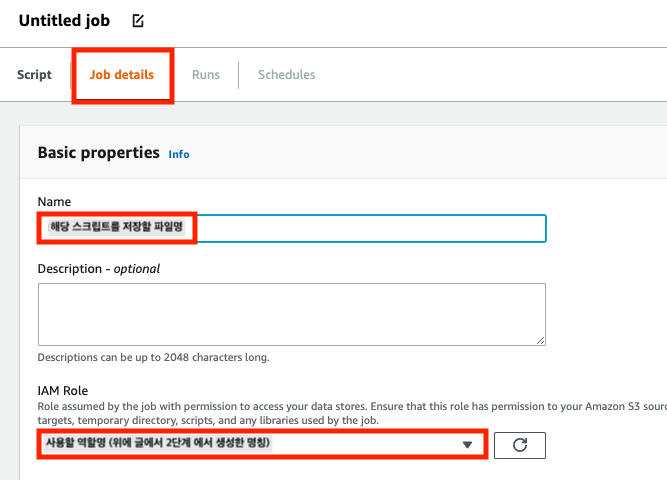
이제 Job details 를 클릭하여 상세적인 정보를 넣는다.
Name 부분 변경시 전체적으로 상단 파일명, 하단에 script filename 부분이 자동으로 변경 된다.
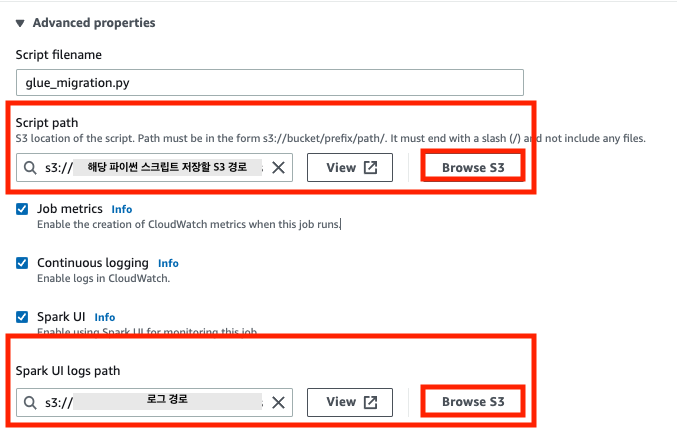
python library path 는 앞전에 S3 에 업로드한 스크립트의 경로를 입력하면 된다.
Job parameters 는 아래와 같다.
--database-names : 이관 대상 데이터 베이스명 (여러개일시 ';' 로 구분하여 나열한다. > 예 : A;B;C)
--mode : to-s3
--output-path : 메타데이터 저장 S3 경로 (뒤에 '/' 를 꼭 붙인다. > 예 : s3://test/)
--region : Region 명 (서울은 'ap-northeast-2')

이제 상단에 Run 을 눌러 실행하고 Run 탭을 눌러 확인하면 진행 완료시 아래와 같이 success 문구를 볼수 있다.

이제 'output-path' 로 지정한 S3 경로로 가보면 '날짜-시-분-초' 경로가 생성 되었으며 가보면 아래와 같이 데이터 베이스, 파티션, 테이블 경로가 생성 되었다.

경로에 들어가서 확인해보면 Json 파일 형태로 저장 되어 있다.

// databases
{
"type":"database",
"item":{
"description":"[데이터 베이스명] Hive database",
"locationUri":"[데이터베이스 S3 경로]",
"name":"[데이터 베이스 명]"
}
}// tables
{
"database":"default",// 데이터베이스 명
"type":"table", // 테이블 명
"item":{
"createTime":"1657616860000",
"lastAccessTime":"0",
"owner":"hadoop",
"retention":0,
"name":"test",
"tableType":"MANAGED_TABLE",
"parameters":{
"transient_lastDdlTime":"1657616859",
"bucketing_version":"2"
},
"partitionKeys":[ // 파티션 명
{
"name":"yyyy",
"type":"int"
}
],
"storageDescriptor":{
"inputFormat":"org.apache.hadoop.mapred.TextInputFormat",
"compressed":false,
"storedAsSubDirectories":false,
"location":"[테이블 S3 경로]",
"numberOfBuckets":-1,
"outputFormat":"org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"bucketColumns":[
],
"columns":[ // 칼럼정보
{
"name":"id",
"type":"int"
}
],
"parameters":{
},
"serdeInfo":{
"serializationLibrary":"org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe",
"parameters":{
"serialization.format":"1"
}
},
"skewedInfo":{
"skewedColumnNames":[
],
"skewedColumnValueLocationMaps":{
},
"skewedColumnValues":[
]
},
"sortColumns":[
]
}
}
}// partitions
{
"database":"default", // 데이터베이스명
"table":"test", // 테이블명
"type":"partition",
"item":{
"creationTime":"1657616899000",
"lastAccessTime":"0",
"namespaceName":"default", // 데이터베이스명
"tableName":"test", // 테이블명
"parameters":{
"transient_lastDdlTime":"1657616899",
"totalSize":"2",
"numRows":"1",
"rawDataSize":"1",
"COLUMN_STATS_ACCURATE":"{\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"id\":\"true\"}}", // 칼럼 정보
"numFiles":"1"
},
"storageDescriptor":{
"inputFormat":"org.apache.hadoop.mapred.TextInputFormat",
"compressed":false,
"storedAsSubDirectories":false,
"location":"[파티션 경로]",
"numberOfBuckets":-1,
"outputFormat":"org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"bucketColumns":[
],
"columns":[ // 칼럼 정보
{
"name":"id",
"type":"int"
}
],
"parameters":{
},
"serdeInfo":{
"serializationLibrary":"org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe",
"parameters":{
"serialization.format":"1"
}
},
"skewedInfo":{
"skewedColumnNames":[
],
"skewedColumnValueLocationMaps":{
},
"skewedColumnValues":[
]
},
"sortColumns":[
]
},
"values":[
"2022" // 생성된 파티션 값
]
}
}데이터 확인 완료 하였으면 이제 [2]번 작업을 진행해보자!
[2] S3 > 메타 스토어로 지정한 DB 에 최종 이관
우선 하이브 메타 스토어에 연결하기 위한 connector 를 다운 받아 s3 에 업로드 한다.
저자의 경우 Aurora DB 사용하고 있어 맞는 버전의 mysql connector 를 다운 받아서 s3에 업로드 하였다. 각자 맞는 connector 를 다운로드 한다.
$ wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.42.tar.gz마이그레이션을 위한 스크립트에 빈칸을 채우고 S3 에 업로드한다.
// start_migration_s3_to_aurora.sh
input_path 는 [1] 에서 output-path 으로 지정한 경로 + 생성된 '날짜+시+분+초' 로 된 경로 (끝에 / 를 붙여야 합니다.)
MYSQL_JAR_PATH=/usr/lib/hadoop/mysql-connector-java-5.1.42-bin.jar
DRIVER_CLASSPATH=/home/hadoop/*:/etc/hadoop/conf:/etc/hive/conf:/usr/lib/hadoop-lzo/lib/*:/usr/lib/hadoop/hadoop-aws.jar:/usr/share/aws/aws-java-sdk/*:/usr/share/aws/emr/emrfs/conf:/usr/share/aws/emr/emrfs/lib/*:/usr/share/aws/emr/emrfs/auxlib/*:$MYSQL_JAR_PATH
spark-submit --driver-class-path $DRIVER_CLASSPATH \
--jars $MYSQL_JAR_PATH \
/home/hadoop/hive_metastore_migration.py \
--mode to-metastore \
--jdbc-url jdbc:mysql://[IP]:[PORT]/[DATABASE]?useSSL=false \
--jdbc-user [CONNETION USERNAME] \
--jdbc-password [CONNETION PASSWORD] \
--input_path s3://[PATH]/이제 부트스트랩을 아래와 같이 만든뒤 S3 에 업로드 한다.
// setting_for_glue_migration.sh
sudo aws s3 cp s3://[경로]/mysql-connector-java-5.1.42-bin.jar /usr/lib/hadoop/mysql-connector-java-5.1.42-bin.jar
sudo aws s3 cp s3://[경로]/hive_metastore_migration.py /home/hadoop/hive_metastore_migration.py
sudo aws s3 cp s3://[경로]/start_migration_s3_to_aurora.sh /home/hadoop/start_migration_s3_to_aurora.sh
sudo chmod 777 /home/hadoop/start_migration_s3_to_aurora.sh// hive_metastore_migration.py
AWS 에서 제공하는 파일을 사용해도 되며, 저자는 오류나는 부분 수정하여 아래 git 에 업로드 하였으니 참고 하면 된다.
:: https://github.com/works-code/aws-files.git
GitHub - works-code/aws-files
Contribute to works-code/aws-files development by creating an account on GitHub.
github.com
그다음 EMR 을 생성하며 S3 에 업로드한 부트스트랩을 포함하여 실행하며 아래 두가지 중에 해당하는 EMR 생성 방법으로 진행한다.
// AWS UI


// Lambda
BootstrapActions=[
{
"Name": "setting_for_glue_migration.sh",
"ScriptBootstrapAction": {
"Path": "s3://[경로]/setting_for_glue_migration.sh"
}
}
],..
부트스크랩까지 정상적으로 실행 되었다면 (EMR 대기 상태이면 성공/ 부트스트랩 실패시 EMR은 종료된다.)
EMR 에 접속하여 스크립트를 실행한다.
$ ./start_migration_s3_to_aurora.sh아래와 같은 로그를 볼수 있다.
2022-07-14 12:41:18,118 INFO spark.SparkContext: Running Spark version 3.1.1-amzn-0.1
2022-07-14 12:41:18,159 INFO resource.ResourceUtils: ==============================================================
2022-07-14 12:41:18,160 INFO resource.ResourceUtils: No custom resources configured for spark.driver.
2022-07-14 12:41:18,160 INFO resource.ResourceUtils: ==============================================================
2022-07-14 12:41:18,161 INFO spark.SparkContext: Submitted application: hive_metastore_migration.py
2022-07-14 12:41:23,747 INFO yarn.Client: Application report for application_1657800948325_0011 (state: ACCEPTED)
2022-07-14 12:41:23,750 INFO yarn.Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1657802482718
final status: UNDEFINED
tracking URL: http://ip-.....ap-northeast-2.compute.internal:20888/proxy/application_1657800948325_0011/
user: hadoop
2022-07-14 12:41:27,267 INFO util.Utils: Using initial executors = 50, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances
2022-07-14 12:41:27,278 WARN cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request executors before the AM has registered!
2022-07-14 12:41:27,297 INFO cluster.YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0완료 되고 hive 에 접속하여 보면 정상적으로 반영 된것을 확인 할 수 있다.
$ hive
hive> show databases;
a
b
c끝!
'BIG DATA' 카테고리의 다른 글
| [EMR] ORC 테이블 ClassCastException 오류 발생 (0) | 2022.08.03 |
|---|---|
| [EMR] Hive StatsTask 이슈 (0) | 2022.08.03 |
| [EMR] 해결한 이슈 항목 (0) | 2022.05.27 |
| [AWS] 스노우볼을 이용한 데이터 이관 (0) | 2022.05.21 |
| [Redash] Ldap 연동 해보자! (0) | 2022.05.08 |

