
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- gradle
- ec2
- 클러스터
- 로그인
- Jenkins
- 젠킨스
- Cluster
- Mac
- EMR
- 간단
- java
- fastcampus
- 예제
- config
- Zeppelin
- 자동
- 레디스
- spring
- Kafka
- 머신러닝
- 설정
- 자바
- aws
- login
- redash
- vue
- Docker
- hive
- Redis
- SpringBoot
- Today
- Total
코알못
[AWS] RedShift 이용해보자! 본문

RedShift는 EMR 같이 분산 처리 파일 시스템으로 저장소, 분석 쿼리 돌릴시 사용 가능하다.
구글링 하면 EMR 보다는 성능이 좋고, 한번 조회된 쿼리에 대해서 캐싱을 하여 반복된 쿼리 호출에 대해서는 1s 내에 응답한다.
그러나 EMR 보다는 가격이 비싸 빠르게 처리해야하는 데이터의 경우에는 RedShift 를 이용해 처리하면 좋을 것 같다.
비용은 시간당 비용이 나가면 EC2 처럼 일시정지 기능이 있어 정지하여 정지 시간 동안 결제 중단 가능하다.
우선 RedShift 클러스터를 생성한다.
- AWS 콘솔 로그인 > RedShift 검색 > 클러스터 생성
생성을 위해서 필수로 변경 해야 하는 '명칭, 서버 스펙, 서버수, VPC, DB 계정 정보'를 입력하고 나머지는 기본값으로 지정한다.





만들어졌다.
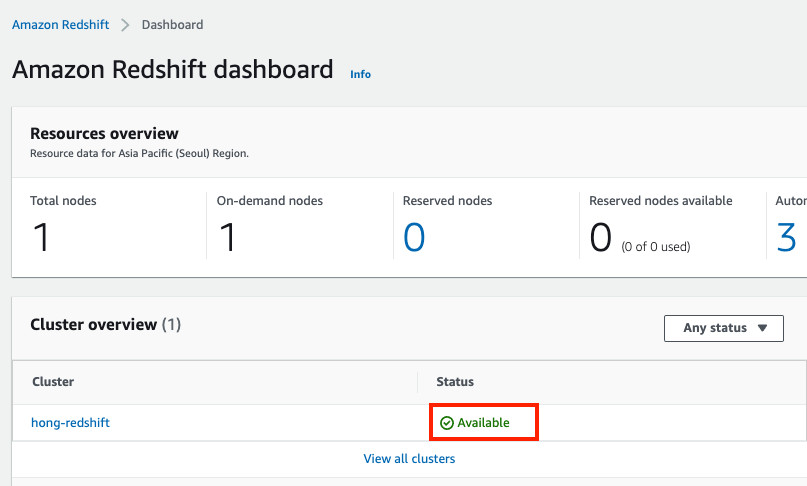
간단하게 테스트 한다.

처음에 쿼리 수행시 아래와 같은 창이 뜬다.

아래와 같이 정상적으로 연결 된것을 볼 수 있다.

s3 데이터는 아래와 같다.
1,ParkHyunJun
2,LeeHoSeong
3,thewayhj
4,LeeNow
5,hongYooLee테이블을 만든다.
create table tb_user(
no integer,
name varchar(20)
);참고로 테이블 생성시 public schema 에 생성된다.

s3 데이터를 복사 하여 가져온다.
아래 키 기반(해당 사용자 key, secret 생성 하여 이용) 인증, 역할 기반 인증(s3에 접근 가능한 IAM을 생성하여 이용)을 통해서 s3 데이터 참조 가능하다.
// 키 기반 인증
COPY tb_user FROM 's3://...'
CREDENTIALS 'aws_access_key_id=<access-key-id>;aws_secret_access_key=<secret-access-key>'
delimiter ',';
// 역할 기반 인증 (아래 IAM 역할 생성 참고하여 생성한 arn 복사해서 이용하면 된다.)
COPY tb_user FROM 's3://...'
IAM_ROLE 'arn:aws:iam::<aws-account-id>:role/<role-name>'
delimiter ',';조회를 하면
select * from tb_user;아래와 같이 데이터가 나온다.

간단하게 사용방법을 알았으며
redshift 가 hive, spark 보다 빠른 성능을 가진다고 하여 실제로 그런지 테스트를 해볼 것이다.
우선 스팩을 맞춘다.
| DB | TYPE | vCPU | MEM | PCS | Total |
| redshift | ra3.xlplus | 4 vcpu | 32GB | 6 pcs | 24 vcpu / 192GB |
| hive/spark | r5.xlarge | 4 vcpu | 32GB | 6 pcs | 24 vcpu / 192GB |
// 테스트 쿼리
-- hive
select t1.uno, t2.song_id from genie_log.tb_user_favority t1 join (select song_id, concat_ws('|',collect_set(string(lowcode_id))) as lowcode_ids from genie_meta.tb_lb_song_tag group by song_id) t2 on t2.lowcode_ids like '%'+t1.library_country_id+'%' and t2.lowcode_ids like '%'+t1.library_genre_id+'%' and t2.lowcode_ids like '%'+t1.library_music_style_id+'%' and t2.lowcode_ids like '%'+t1.library_genre_style_id+'%' and t2.lowcode_ids like '%'+t1.library_year_id+'%' limit 10;
-- spark
select t1.uno, t2.song_id from genie_log.tb_user_favority t1 join (select song_id, concat_ws('|',collect_set(string(lowcode_id))) as lowcode_ids from genie_meta.tb_lb_song_tag group by song_id) t2 on t2.lowcode_ids like concat('%',t1.library_country_id,'%') and t2.lowcode_ids like concat('%',t1.library_genre_id,'%') and t2.lowcode_ids like concat('%',t1.library_music_style_id,'%') and t2.lowcode_ids like concat('%',t1.library_genre_style_id,'%') and t2.lowcode_ids like concat('%',t1.library_year_id,'%') limit 10;
-- redshift
select t1.uno, t2.song_id from tb_user_favority t1 join (select song_id, listagg(lowcode_id,'|') as lowcode_ids from tb_lb_song_tag group by song_id) t2 on t2.lowcode_ids like '%'+t1.library_country_id+'%' and t2.lowcode_ids like '%'+t1.library_genre_id+'%' and t2.lowcode_ids like '%'+t1.library_music_style_id+'%' and t2.lowcode_ids like '%'+t1.library_genre_style_id+'%' and t2.lowcode_ids like '%'+t1.library_year_id+'%' limit 10;// 조건 추가한 테스트 쿼리
-- hive
select t1.uno, t2.song_id from genie_log.tb_user_favority t1 join (select song_id, concat_ws('|',collect_set(string(lowcode_id))) as lowcode_ids from genie_meta.tb_lb_song_tag group by song_id) t2 on t2.lowcode_ids like '%'+t1.library_country_id+'%' and t2.lowcode_ids like '%'+t1.library_genre_id+'%' and t2.lowcode_ids like '%'+t1.library_music_style_id+'%' and t2.lowcode_ids like '%'+t1.library_genre_style_id+'%' and t2.lowcode_ids like '%'+t1.library_year_id+'%' where t1.uno=312188570;
-- spark
select t1.uno, t2.song_id from genie_log.tb_user_favority t1 join (select song_id, concat_ws('|',collect_set(string(lowcode_id))) as lowcode_ids from genie_meta.tb_lb_song_tag group by song_id) t2 on t2.lowcode_ids like concat('%',t1.library_country_id,'%') and t2.lowcode_ids like concat('%',t1.library_genre_id,'%') and t2.lowcode_ids like concat('%',t1.library_music_style_id,'%') and t2.lowcode_ids like concat('%',t1.library_genre_style_id,'%') and t2.lowcode_ids like concat('%',t1.library_year_id,'%') where t1.uno=312188570;
-- redshift
select t1.uno, t2.song_id from tb_user_favority t1 join (select song_id, listagg(lowcode_id,'|') as lowcode_ids from tb_lb_song_tag group by song_id) t2 on t2.lowcode_ids like '%'+t1.library_country_id+'%' and t2.lowcode_ids like '%'+t1.library_genre_id+'%' and t2.lowcode_ids like '%'+t1.library_music_style_id+'%' and t2.lowcode_ids like '%'+t1.library_genre_style_id+'%' and t2.lowcode_ids like '%'+t1.library_year_id+'%' where t1.uno=312188570;테스트 결과,
hive는 실행 완료시 까지 많은 시간이 소요 되어 중단하였으며
redshift 가 spark 에 비해 33.3% 빠르며
만약 조건을 추가 한다면 redshift 가 spark 에 비해 97.9% 빠르며
결론적으로 'redshift > spark > hive' 순으로 빠르다.
| 종류 | 처리 시간 | 조건 추가 |
| hive | 1h 30m 이상 10m 이후 메모리 25%만 사용하며, reduce 작업이 오래 소요 10m 부터 진행률이 계속적으로 83% 라서 중단 |
- |
| spark | 12s > 1s > 1s | 6m 23s > 6m 2s > 6m 24s |
| redshift | 4s > 1s > 1s | 6s > 1s > 1s |
| redshift (외부 테이블) | 2s > 2s > 2s | 2s > 2s > 2s |
redshift 를 이용하면 작년에 유사곡 추천을 위해 hive 쿼리로 많은 시간이 소요되어 하지 못했던 기획을 다시 할 수 있을 것 같다.
그러나 redshift copy 의 경우 참조 개념이 아닌, 복사 개념으로 변경된 데이터를 읽어 올 수 없으며 일일히 데이터를 복사하여 redshift 저장소에 옮기는 작업이 필요하다.
그리고 overwrite 기능을 제공하고 있지 않아 데이터를 삭제하고 데이터를 넣는 작업이 필요하다.
그래서 좀 더 원활한 작업을 위해 copy 가 아닌 redshift spectrum 을 이용하여 데이터 로드 없이 s3에서 바로 쿼리 해보도록 한다. (https://docs.aws.amazon.com/redshift/latest/dg/c-getting-started-using-spectrum.html)
1. IAM 역할 생성 (redshift > AmazonS3ReadOnlyAccess 및 AWSGlueConsoleFullAccess 권한 부여)
- IAM > 역할 > 역할 만들기

- [AmazonS3ReadOnlyAccess], [AWSGlueConsoleFullAccess or AmazonAthenaFullAccess] 권한 선택
저자는 glue 를 사용하기에 [AmazonAthenaFullAccess] 가 아닌 [AWSGlueConsoleFullAccess] 를 선택한다.


- 역할 이름 'AWSRedshiftToS3AndGlueAccess' 로 지정, 태그 지정 후 역할 생성


- 역할 'AWSRedshiftToS3AndGlueAccess' 검색하여 ARN(Amazon Resource Number) 복사


2. redshift 클러스터와 역할 연결
Redshift > 클러스터 > 클러스터 이름 클릭 > 속성 > IAM 역할 연결 > 이전에 만든 역할 'AWSRedshiftToS3AndGlueAccess' 클릭후 associate IAM roles 클릭

2. 외부 스키마 생성
create external schema spectrum_schema // Redshift 에 spectrum_schema 스키마 생성
from data catalog // glue or athena metastore 이용 (data catalog 이외에 hive metastore를 입력하여 hive의 메타 스토어로 이용 가능)
database 'glue or athena 에 생성할 DB명'
iam_role 'arn:aws:iam::746920558207:role/AWSRedshiftToS3AndGlueAccess' // redshift arn
create external database if not exists; // metastore에 생성하려는 데이터 베이스가 없을시에만 생성하며, 있다면 해당 데이터베이스를 이용한다.

glue 에 들어가서 보면 정상적으로 생성 되었다.

3. 외부 테이블 생성하여 s3 데이터 읽기
create external table spectrum_schema.tb_user(
no integer,
name varchar(20))
row format delimited
fields terminated by ','
stored as textfile
location 's3://.../tb_user/';생성 된것을 볼 수 있다.

Glue 가서 보면 테이블이 생성 된것을 볼 수 있다.

조회하면 데이터 정상적으로 나온다.

외부 스키마 생성시 glue DB 명을 지정하는데 이미 존재하는 DB라면 해당 데이터 베이스에 생성 되어있는 테이블 모두 접근 가능하며
Redshift 스키마를 삭제 하더라도 glue 와 연결 되어있는 DB, Table 은 모두 삭제 되지 않는다.
drop schema spectrum_schema;
create external schema spectrum_schema
from data catalog
database '...'
iam_role '...'
create external database if not exists;스키마를 삭제하고 다시 생성시 테이블 정보가 그대로 있다.

데이터 조회시 정상적으로 조회 된다.

만약 바라보고 있는 s3 위치의 데이터가 변경 되면 정상적으로 읽어 올까? 변경하고 조회해본다.
// 6,test 추가
1,ParkHyunJun
2,LeeHoSeong
3,thewayhj
4,LeeNow
5,hongYooLee
6,test정상적으로 읽어 온다.

외부 스키마 테이블 생성하여 s3 데이터에 바로 접근시 성능적으로 차이가 없는지 확인 한다.
create external schema xx_log
from data catalog
database 'xx_log'
iam_role 'arn:aws:iam::11:role/AWSRedshiftToS3AndGlueAccess'
create external database if not exists;
create external schema xx_meta
from data catalog
database 'xx_meta'
iam_role 'arn:aws:iam::11:role/AWSRedshiftToS3AndGlueAccess'
create external database if not exists;

필요한 테이블을 생성한다.
create external table genie_meta.tb_lb_song_tag(
song_id integer,
lowcode_id varchar)
row format delimited
fields terminated by ','
stored as textfile
location 's3://..._meta/tb_lb_song_tag/';정상적으로 glue 에 생성 됨을 확인 할 수 있다.
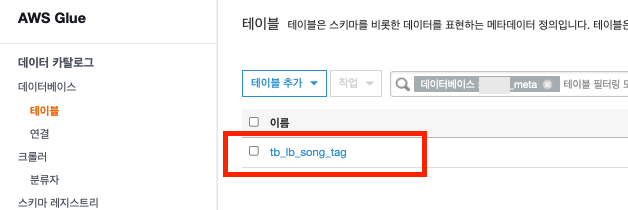
테이블을 생성한다.
create external table genie_log.tb_user_favority(
uno integer,
service_genre_id varchar,
service_genre_text varchar,
library_country_id varchar,
library_country_text varchar,
library_genre_id varchar,
library_genre_text varchar,
library_music_style_id varchar,
library_music_style_text varchar,
library_genre_style_id varchar,
library_genre_style_text varchar,
library_year_id varchar,
library_year_text varchar,
library_country_song_ids varchar,
library_music_style_song_ids varchar,
library_genre_style_song_ids varchar,
service_genre_song_ids varchar)
stored as textfile
location 's3://..._log/tb_user_favority/';정상적으로 glue 에 생성 됨을 확인 할 수 있다.

테스트 결과,
외부 테이블을 사용하면 쿼리 성능이 copy해서 접근하는 것 보다 빠르나 캐싱이 되지 않기에 추가 호출시 쿼리 소요 시간이 단축되지 않는다.
그러나 저자가 운영하고 있는 분석 시스템 이용자들은 한번 조회한 쿼리를 계속적으로 호출하는 경우가 많지 않을 것이며
외부 테이블을 사용하지 않으면 불필요하게 데이터를 두벌로 가지고 있어야 하는 단점이 있기에 외부 테이블을 이용하고자 한다.
목적에 맞게 테이블을 생성하면 될 것 같다.
| 방식 | 소요 시간 | 소요 시간 |
| redshift | 4s > 1s > 1s | 6s > 1s > 1s |
| redshift (외부 테이블) | 2s > 2s > 2s | 2s > 2s > 2s |
이제 기획자나, 개발자들이 사용하는 BI 툴(tableau, redash, zeppelin 등)에서 Redshift 를 이용할 수 있는지 검토한다.
// tableau
- 연결

- 결과 화면

redash, zepplien 도 redshift 와 연동할 수 있다고 하며 사용하게 된다면 그때 연동 해보도록 한다.
그 다음 알아볼것은 redshift 운영 방안이다.
계속적으로 클러스터를 띄워두는 것으로도 비용이 나가기에 예약된 일시 중지 기능을 이용하여 사용하는 시간이나 주에만 활성화 되도록 할 수 있다.

스케쥴러 실행 시키려고 하였으나 아래와 같이 IAM 권한이 필요하다고 하여 추가하도록 한다.

우선 위에서 생성한 Redshift 권한 상세 보기로 들어가서 '신뢰 정책 편집' 을 클릭하여 service 부분에 'scheduler.redshift.amazonaws.com' 를 추가한다.

// 기존
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "redshift.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}// 변경
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"scheduler.redshift.amazonaws.com",
"redshift.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}변경하여 저장한뒤 다시 스케쥴 설정하는 부분을 들어가면 '역할 선택' 부분에 선택할수 있는 보기가 없었으나 추가 되었다.

역할 선택을 한 뒤 '반복 일시 중지 및 재개 예약' 버튼을 클릭하면 성공적으로 스케쥴링이 예약 되고
클러스터 '상세 정보 > 일정' 클릭시 예약된 작업을 볼 수 있다.

중단이 아닌 일시 정지 이므로 이미 생성한 S3를 바라보고 있는 외부 테이블은 제거 되지 않으니 redshift가 재개 되면 바로 사용하면 된다.
만약 redshift 로 배치를 돌리고 싶다면 zepplien 이나 redash 의 스케쥴 기능을 이용하여 배치화 하면 된다.
끝!
<참고>
1. 오류 로그 확인 방법
-- 오류 확인
select * from stl_load_errors;2. 쿼리 캐싱 사용 여부 확인
- source_query 에 NULL 이 아닌 쿼리 번호가 있다면 해당 쿼리 번호의 캐싱된 데이터 사용
select userid, query, elapsed, source_query from svl_qlog
where userid > 1
order by query desc;// 결과
- 10852, 10856 번 쿼리의 경우 10845번 쿼리 결과를 캐싱
- 10838의 경우 캐싱 된 데이터 미 사용

'BIG DATA' 카테고리의 다른 글
| [ Zeppelin] JDBC 인터프리터를 추가 해보자! (0) | 2022.04.18 |
|---|---|
| [Redash] 권한별 DB 접근 제어를 해보자! (0) | 2022.04.18 |
| [AWS] Kafka connector 분산 처리 (2) | 2022.03.09 |
| [ Zeppelin] 계정별로 권한을 설정해보자! (0) | 2022.03.07 |
| [ Zeppelin] 스케쥴링 기능을 이용해보자! (0) | 2022.03.07 |



